Z tohto príkazu nájdeme dve funkcie popísané vyššie. -Chcem tým ignorovať prípad, kdekoľvek sa použije toto kľúčové slovo, sa náklonnosť k prípadu odstráni.
Predpoklad
Na splnenie funkčnosti tejto funkcie v operačnom systéme Linux je potrebné mať nainštalovaný operačný systém Linux. Po nakonfigurovaní poskytnete požadované informácie o používateľovi, pomocou ktorých bude používateľ prihlásený. Po zadaní používateľského mena a hesla bude mať používateľ navyše prístup ku všetkým vstavaným funkciám operačného systému. Nakoniec, po prístupe na plochu sa od vás vyžaduje prístup k terminálu, pretože sa na ňom musia spúšťať príkazy.
Príklad 1:
V tomto príklade uvidíme, ako grep pomáha vyhnúť sa rozlišovaniu malých a veľkých písmen. Zvážte súbor s názvom files11.TXT. Súbor obsahuje nasledujúce údaje; ako vidíte, slovo mango je napísané rôznymi spôsobmi, niektoré slová sú veľké a niektoré malé. Pomocou príkazu cat zobrazíme údaje súboru.
$ súbory mačiek11.TXT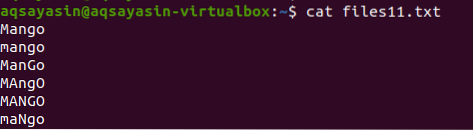
Len čo sa príkaz použije na zobrazenie údajov, je možné pozorovať, že sa zobrazí jediné slovo, ktoré sa zhoduje s veľkým písmenom v príkaze. Všetky písmená sú malé.
$ grep súbory manga11.TXT
Teraz, aby sme pochopili koncept necitlivosti na malé a veľké písmená, použijeme v príkaze „-I“ na zvládnutie malých a veľkých písmen tým, že poskytneme všetky údaje prítomné v súbore, pričom sa zhodujú s reťazcom prítomným vo vnútri príkazu.
$ grep -I mango súbory11.TXT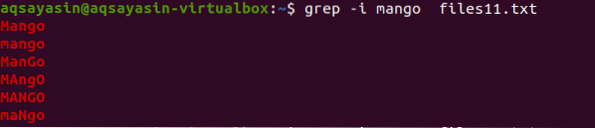
Z výstupu zistíte, že všetky údaje, ktoré sa zhodujú so slovom „mango“, sa zobrazia buď pri niektorých slovách, ktoré sú napísané veľkými písmenami, a niektoré sú malými písmenami.
Príklad 2
Tento príklad sa podobá prvému, rozdiel je v tom, že sa získa iba jedno slovo. Tento príkaz pomáha získať celý reťazec tak, že ho porovná so slovom uvedeným v príkaze. Dajme si spis.TXT. ako príklad chceme načítať záznam podľa danej zhody.
$ mačka filea.TXT
Teraz použite rovnaký príkaz na ignorovanie malých a veľkých písmen a vykreslenia výstupu. Odborné slovo sa zobrazuje vylúčením veľkých a malých písmen.

Príklad 3
Ďalším spôsobom použitia grep na ignorovanie malých a veľkých písmen je najskôr vložiť názov súboru a neskôr použiť príkaz -I s grepom nasledujúcim po „|“ operátor. Mačka sa používa v spojení s „|“. Vytvorme si súbor s názvom file24.TXT. ako príklad.
$ Cat súbor24.txt | grep -I „Aqsa“Tento príkaz načíta slovo „Aqsa“ veľkými aj malými písmenami.

Príklad 4
Pohybom k ďalšiemu príkladu. Tu zobrazíme údaje súboru, ktorý obsahuje slovo „môj“. Tu sa vyhľadávanie vykonáva zavedením adresára, takže príkaz zoradí slovo vo všetkých súboroch s príponou .txt v systéme.
$ grep -I môj / domov / aqsayasin / *.TXT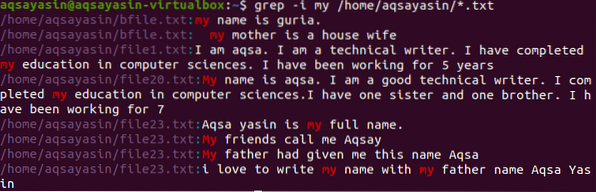
Vyššie uvedený obrázok zobrazuje výstup získaný z príkazu. „Moje“ slovo je zvýraznené, to je v obidvoch prípadoch. Niektoré súbory ho obsahujú malými písmenami, zatiaľ čo iné ho obsahujú veľkými písmenami. Zobrazí sa tiež adresa súborov a názvy súborov.
Príklad 5
Tento príklad je možné použiť na adresár, v ktorom sú všetky súbory. Na zobrazenie konkrétneho výsledku, ktorý sa zhoduje so slovom, ktoré sme definovali v príkaze, sa uplatnia obmedzenia. Slovo „je“ sa používa na vyhľadávanie vo všetkých súboroch v systéme.
$ grep -I je / home / aqsayasin / súbor *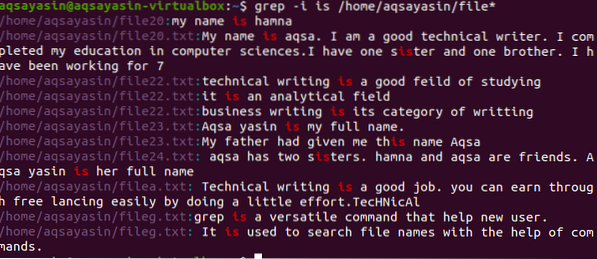
Výstup zobrazuje celé reťazce, ktoré v ňom obsahujú zhodné slovo. Pretože „je“ sa píše osobitne alebo kombinuje sa s iným slovom, t.j.e. sestra.
Príklad 6
Nasledujúci príkaz ukazuje, ako -iw v príkaze funguje spoločne. Okrem toho sa tu hľadajú aj dve slová v jednom súbore. Spätné lomítko a znak „|“ sa používajú na popísanie dvoch slov v súbore, zatiaľ čo -w sa používa na presnú zhodu príslušného slova v súbore.
$ grep -iw 'hamna \ | house' súbor21.TXT$ grep 'hamn \ | house' súbor21.TXT

-Citlivosť na veľké a malé písmená budem ignorovať. Vo vyššie uvedenom príklade vidíme, že prítomnosť -w s -I umožňuje, aby dom v prvom príkaze nebol braný do úvahy, pretože -w umožňuje presnú zhodu. V druhom príkaze sme odstránili obe -iw, preto sa obe slová zobrazia po zhode v reťazci.
Príklad 7
Viac ako jedno slovo sa vyhľadáva použitím inej metódy. Obe slová sa hľadajú v rovnakom súbore, tieto slová sú „zamestnanie“ a „zarobiť“. Earn je načítaný zo slova learning. Upozorňujeme tiež, že každé slovo je oddelené od kľúčového slova -e.
$ grep -I -e job -e zarobiť filea.TXT
Obrázok vyššie zobrazuje celé reťazce v odseku týkajúce sa slov obsiahnutých v príkaze. Rovnako ako vyššie uvedené príklady, - Ignoroval som každú diskrimináciu slov „zamestnať a zarobiť“.
Príklad 8
V tomto príklade hľadanie dvoch slov prítomných vo všetkých súboroch súboru .rozšírenie txt. Tieto dve slová sú oddelené znakom -e, keďže -e je správna cesta na oddelenie dvoch slov. Získaný výstup bude mať obe slová zobrazené vo všetkých súboroch s textovou príponou. Získa sa celá adresa súboru a zobrazí sa. -Ignorujem rozlišovanie malých a veľkých písmen a zobrazím obe slová prítomné vo všetkých súboroch.
$ grep -I -e práca -e zarobiť / domov / aqsayasin / *.TXT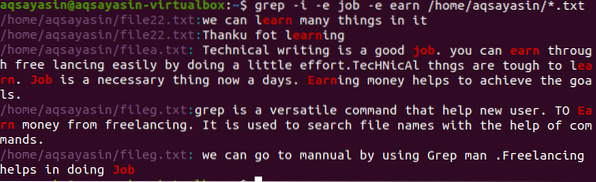
Záver
V tejto príručke sme použili najjednoduchší príklad na rozpracovanie koncepcie rozlišovania malých a veľkých písmen. Snažili sme sa čo najlepšie prejsť každým aspektom, aby sme rozšírili vedomosti týkajúce sa grepu.

