Data Science
Logistická regresia v Pythone
Logistická regresia je algoritmus klasifikácie strojového učenia. Logistická regresia je podobná aj lineárnej regresii. Ale hlavný rozdiel medzi logis...
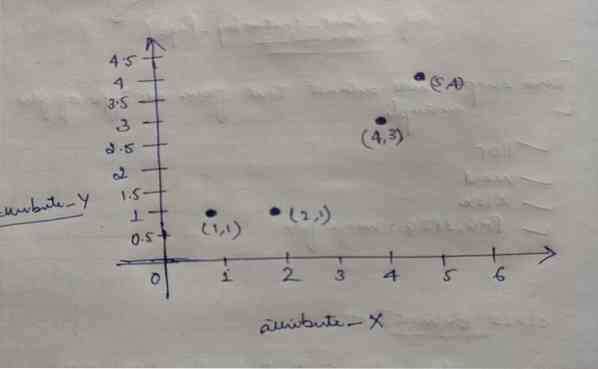
K-znamená zhlukovanie
Kód tohto blogu je spolu s množinou údajov k dispozícii na nasledujúcom odkaze https: // github.com / shekharpandey89 / k-means Zhlukovanie K-Means je...

Ako vytvoriť kontingenčnú tabuľku v Pandas Python
V pandónovom pytóne obsahuje kontingenčná tabuľka funkcie súčtov, počtov alebo agregácií odvodené z dátovej tabuľky. Funkcie agregácie je možné použiť...
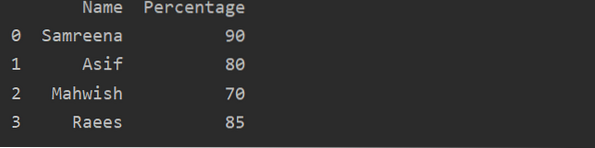
Ako vytvoriť Pandas DataFrame v Pythone?
Pandas DataFrame je 2D (dvojrozmerná) anotovaná dátová štruktúra, v ktorej sú údaje zarovnané vo forme tabuľky s rôznymi riadkami a stĺpcami. Pre jedn...
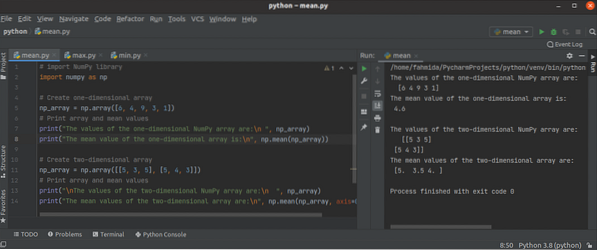
Ako používať funkcie Python NumPy mean (), min () a max ()?
Knižnica Python NumPy má veľa súhrnných alebo štatistických funkcií na vykonávanie rôznych typov úloh pomocou jednorozmerného alebo viacrozmerného poľ...
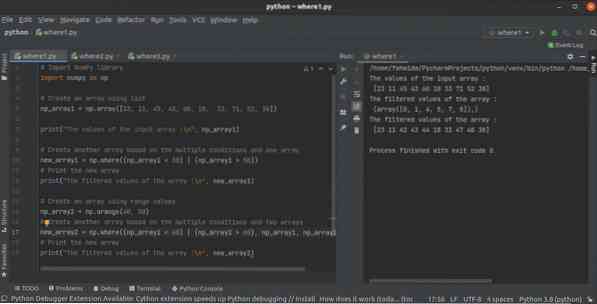
Ako používať python NumPy where () funkciu s viacerými podmienkami
Knižnica NumPy má veľa funkcií na vytvorenie poľa v pythone. kde () je jedna z nich na vytvorenie poľa z iného poľa NumPy na základe jednej alebo viac...
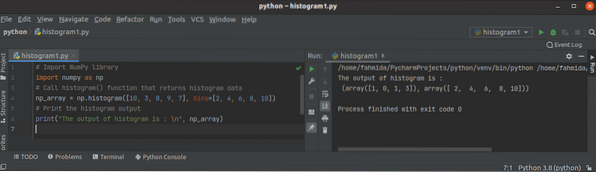
Výukový program pre histogram () Python NumPy
Histogram je mapovanie intervalov na frekvencie. Používa sa na aproximáciu funkcie hustoty pravdepodobnosti konkrétnej premennej. Je známy aj ako stĺp...
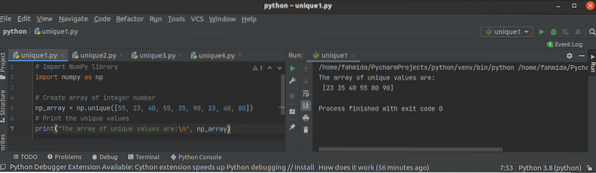
Ako používať funkciu Python NumPy unique ()
Knižnica NumPy sa používa v pythone na vytvorenie jedného alebo viacerých rozmerných polí a má veľa funkcií na prácu s poľom. Funkcia unique () je jed...
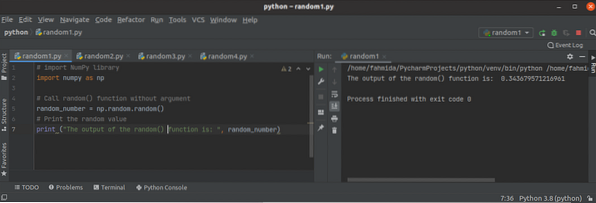
Ako používať náhodnú funkciu Python NumPy?
Keď sa hodnota čísla zmení pri každom vykonaní skriptu, potom sa toto číslo nazýva náhodné číslo. Náhodné čísla sa používajú hlavne na rôzne typy test...