Umiestnenie a výber prvkov z webovej stránky je kľúčom k scrapingu webu so selénom. Na vyhľadanie a výber prvkov z webovej stránky môžete použiť selektor XPath v seléne.
V tomto článku vám ukážem, ako vyhľadať a vybrať prvky z webových stránok pomocou selektorov XPath v seléne s knižnicou selénu python. Takže poďme na to.
Predpoklady:
Ak chcete vyskúšať príkazy a príklady tohto článku, musíte mať,
- Vo vašom počítači je nainštalovaná distribúcia Linuxu (najlepšie Ubuntu).
- Python 3 nainštalovaný na vašom počítači.
- Vo vašom počítači je nainštalovaný program PIP 3.
- Python virtualenv balík nainštalovaný vo vašom počítači.
- Vo vašom počítači sú nainštalované webové prehľadávače Mozilla Firefox alebo Google Chrome.
- Musíte vedieť, ako nainštalovať ovládač Firefox Gecko alebo webový ovládač Chrome.
Pre splnenie požiadaviek 4, 5 a 6 si prečítajte môj článok Úvod do selénu v Pythone 3. Mnoho článkov o ďalších témach nájdete na stránkach LinuxHint.com. Ak potrebujete pomoc, nezabudnite ich skontrolovať.
Nastavenie adresára projektu:
Ak chcete mať všetko usporiadané, vytvorte nový adresár projektu selén-xpath / nasledovne:
$ mkdir -pv selén-xpath / ovládače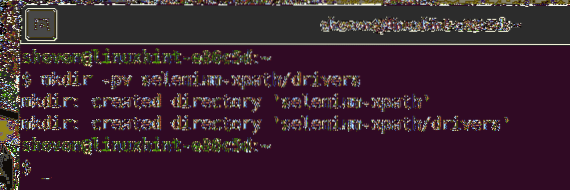
Prejdite na ikonu selén-xpath / adresár projektu nasledovne:
$ cd selenium-xpath /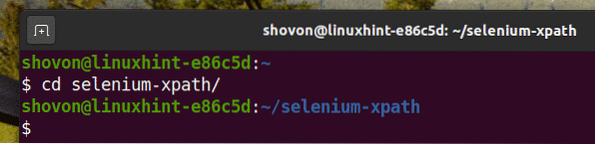
Vytvorte virtuálne prostredie Pythonu v adresári projektu takto:
$ virtualenv .venv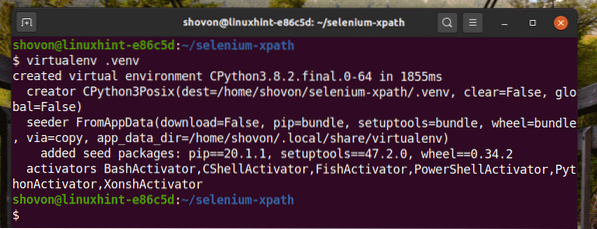
Aktivujte virtuálne prostredie nasledovne:
$ zdroj .venv / bin / aktivovať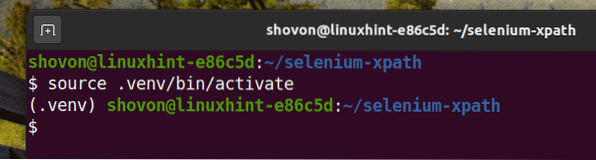
Nainštalujte knižnicu selénu Python pomocou PIP3 nasledovne:
$ pip3 nainštalujte selén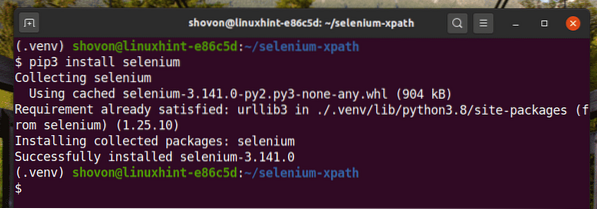
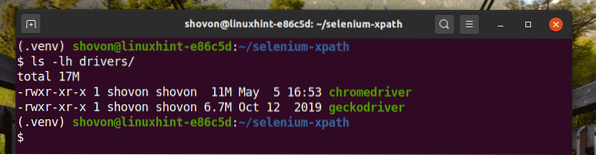
Stiahnite a nainštalujte všetky požadované webové ovládače v vodiči / adresár projektu. V mojom článku som vysvetlil proces sťahovania a inštalácie webových ovládačov Úvod do selénu v Pythone 3.
Získajte nástroj XPath Selector pomocou nástroja pre vývojárov prehliadača Chrome:
V tejto časti vám ukážem, ako pomocou selénu nájsť selektor prvku XPath prvku webovej stránky, ktorý chcete vybrať, pomocou zabudovaného vývojárskeho nástroja webového prehliadača Google Chrome.
Ak chcete získať selektor XPath pomocou webového prehliadača Google Chrome, otvorte prehliadač Google Chrome a navštívte web, z ktorého chcete extrahovať údaje. Potom stlačte pravé tlačidlo myši (RMB) na prázdnej časti stránky a kliknite na Skontrolujte otvoriť Chrome Developer Tool.
Môžete tiež stlačiť
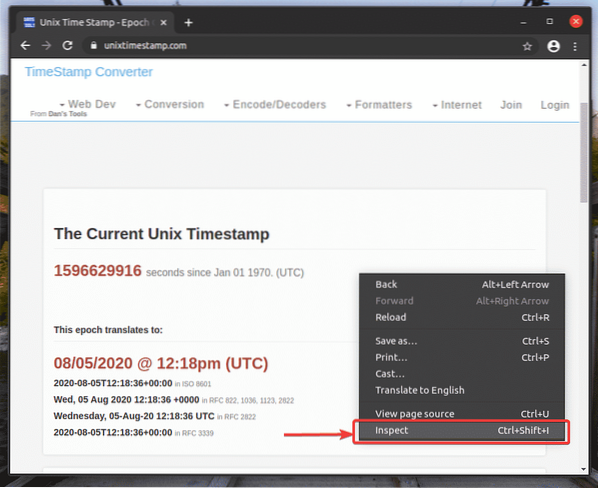
Chrome Developer Tool by mali byť otvorené.
Ak chcete nájsť zastúpenie HTML požadovaného prvku webovej stránky, kliknite na ikonu Skontrolujte(
), ako je to označené na snímke obrazovky nižšie.
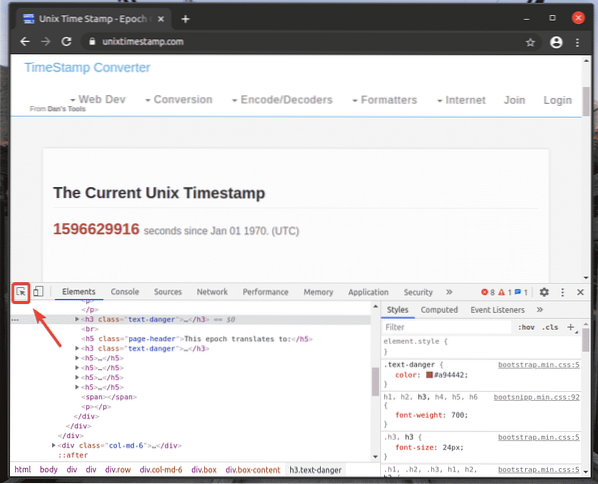
Potom umiestnite kurzor myši nad požadovaný prvok webovej stránky a vyberte ho ľavým tlačidlom myši (LMB).
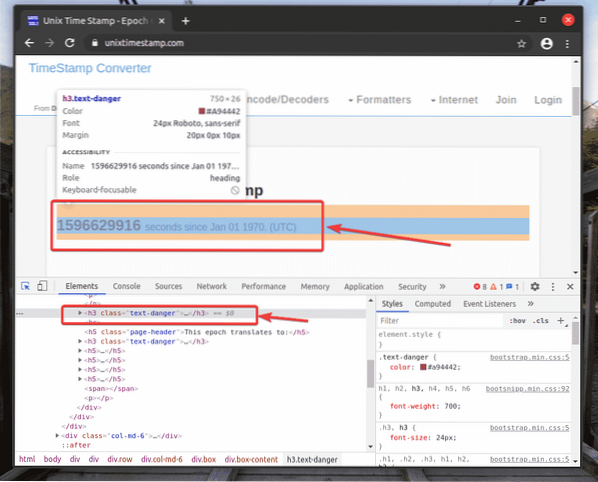
Reprezentácia HTML webového prvku, ktorý ste vybrali, bude zvýraznená v Prvky záložka Chrome Developer Tool, ako vidíte na snímke obrazovky nižšie.
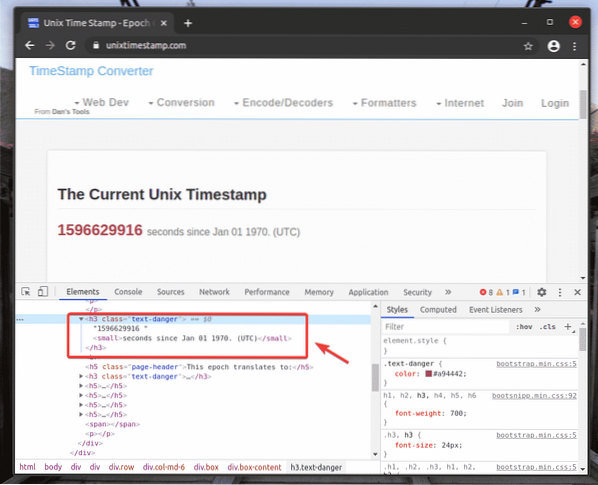
Ak chcete získať selektor XPath požadovaného prvku, vyberte prvok z okna Prvky záložka Chrome Developer Tool a kliknite na ňu pravým tlačidlom myši (RMB). Potom vyberte Kópia > Skopírujte XPath, ako je vyznačené na snímke obrazovky nižšie.
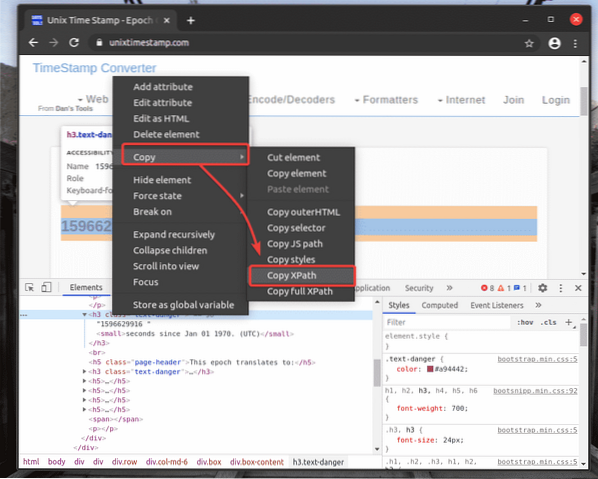
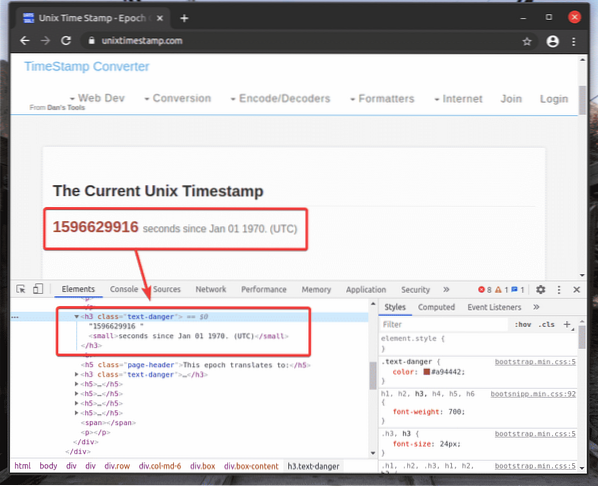
Volič XPath som vložil do textového editora. Selektor XPath vyzerá tak, ako je to znázornené na snímke obrazovky nižšie.

Získajte nástroj XPath Selector pomocou vývojového nástroja Firefox:
V tejto časti vám ukážem, ako pomocou selénu nájsť selektor prvku XPath prvku webovej stránky, ktorý chcete vybrať, pomocou zabudovaného vývojového nástroja webového prehliadača Mozilla Firefox.
Ak chcete získať selektor XPath pomocou webového prehľadávača Firefox, otvorte Firefox a navštívte webovú stránku, z ktorej chcete extrahovať údaje. Potom stlačte pravé tlačidlo myši (RMB) na prázdnej časti stránky a kliknite na Skontrolujte prvok (Q) otvoriť Nástroj pre vývojárov Firefoxu.
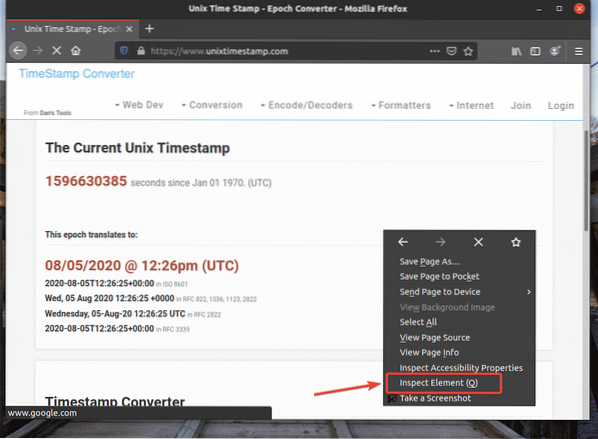
Nástroj pre vývojárov Firefoxu by mali byť otvorené.
Ak chcete nájsť zastúpenie HTML požadovaného prvku webovej stránky, kliknite na ikonu Skontrolujte(
), ako je to vyznačené na snímke obrazovky nižšie.
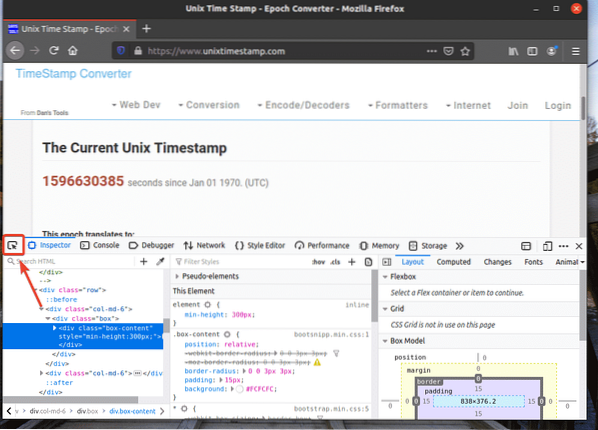
Potom umiestnite kurzor myši nad požadovaný prvok webovej stránky a vyberte ho ľavým tlačidlom myši (LMB).
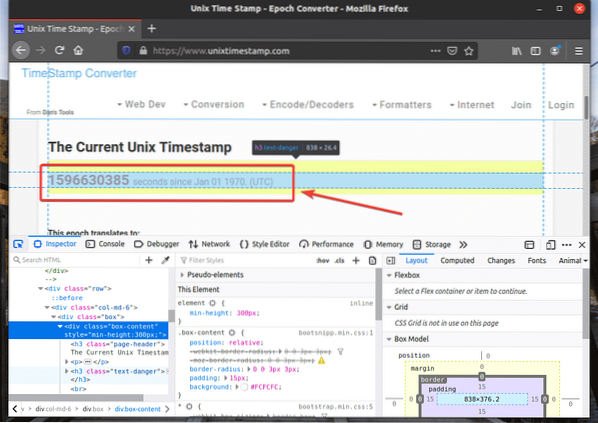
HTML reprezentácia webového prvku, ktorý ste vybrali, bude zvýraznená v Inšpektor záložka Nástroj pre vývojárov Firefoxu, ako vidíte na snímke obrazovky nižšie.
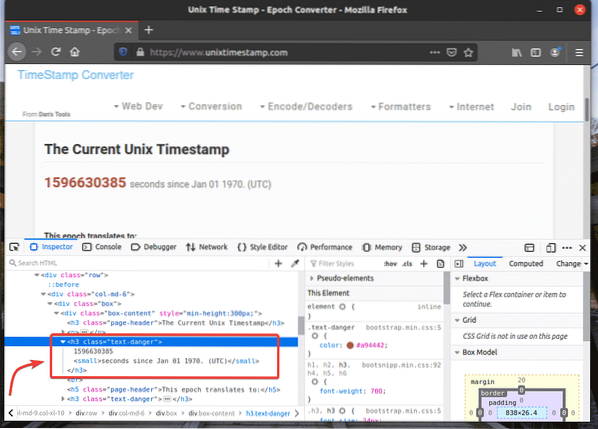
Ak chcete získať selektor XPath požadovaného prvku, vyberte prvok z okna Inšpektor záložka Nástroj pre vývojárov Firefoxu a kliknite na ňu pravým tlačidlom myši (RMB). Potom vyberte Kópia > XPath ako je vyznačené na snímke obrazovky nižšie.
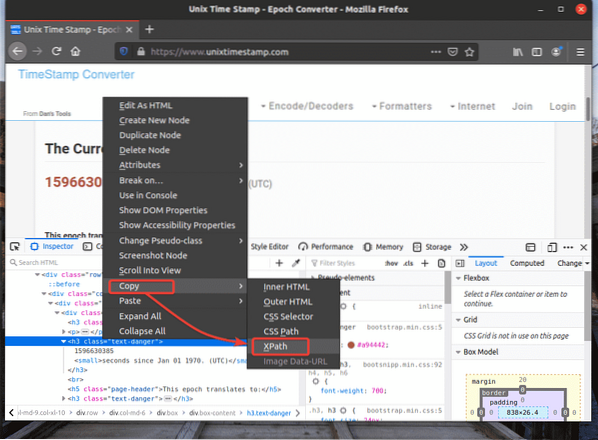
Selektor XPath požadovaného prvku by mal vyzerať asi takto.

Extrakcia údajov z webových stránok pomocou nástroja XPath Selector:
V tejto časti vám ukážem, ako vyberať prvky webových stránok a extrahovať z nich údaje pomocou selektorov XPath s knižnicou Selenium Python.
Najskôr vytvorte nový skript v jazyku Python ex01.py a zadajte nasledujúce riadky kódov.
z webového ovládača na selén na importzo selénu.webdriver.bežné.kľúče na import kľúčov
zo selénu.webdriver.bežné.importom do
options = webdriver.ChromeOptions ()
možnosti.bezhlavý = Pravda
prehliadač = webdriver.Chrome (executable_path = "./ drivers / chromedriver ",
možnosti = možnosti)
prehliadač.get ("https: // www.unixtimestamp.com / ")
timestamp = prehliadač.find_element_by_xpath ('/ html / body / div [1] / div [1]
/ div [2] / div [1] / div / div / h3 [2] ')
print ('Aktuálna časová známka:% s'% (časová známka.text.split (") [0]))
prehliadač.Zavrieť()
Po dokončení uložte súbor ex01.py Skript v jazyku Python.
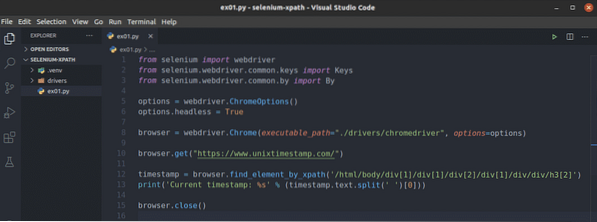
Riadok 1-3 importuje všetky požadované komponenty selénu.

Riadok 5 vytvára objekt Možnosti prehliadača Chrome a riadok 6 umožňuje bezhlavý režim webového prehliadača Chrome.

Riadok 8 vytvára Chrome prehliadač objekt pomocou chromedriver binárne z vodiči / adresár projektu.

Riadok 10 informuje prehliadač, aby načítal webovú stránku unixtimestamp.com.

Riadok 12 vyhľadá prvok, ktorý má zo stránky údaje časových značiek, pomocou selektora XPath a uloží ich do súboru časová značka premenná.
Riadok 13 analyzuje údaje časovej pečiatky z prvku a vytlačí ich na konzolu.

Skopíroval som volič XPath označeného h2 prvok z unixtimestamp.com pomocou nástroja pre vývojárov Chrome.
Riadok 14 zavrie prehliadač.

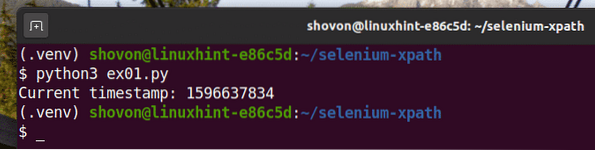
Spustite skript v jazyku Python ex01.py nasledovne:
$ python3 ex01.py
Ako vidíte, údaje o časovej pečiatke sa tlačia na obrazovku.
Tu som použil prehliadač.find_element_by_xpath (selektor) metóda. Jediným parametrom tejto metódy je selektor, čo je selektor XPath prvku.
Namiesto prehliadač.find_element_by_xpath () metódu, môžete tiež použiť prehliadač.find_element (podľa, selektor) metóda. Táto metóda vyžaduje dva parametre. Prvý parameter Autor: bude Autor:.XPATH pretože budeme používať selektor XPath a druhý parameter selektor bude samotný selektor XPath. Výsledok bude rovnaký.
Aby som videl ako prehliadač.find_element () metóda funguje pre selektor XPath, vytvorte nový skript v jazyku Python ex02.py, skopírujte a prilepte všetky riadky z ex01.py do ex02.py a zmeniť riadok 12 ako je vyznačené na snímke obrazovky nižšie.
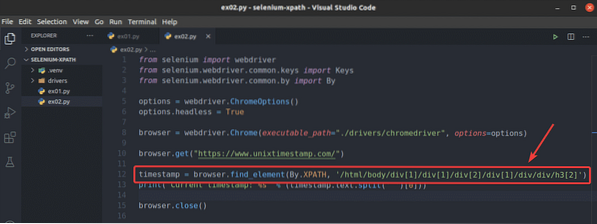
Ako vidíte, skript v jazyku Python ex02.py dáva rovnaký výsledok ako ex01.py.
$ python3 ex02.py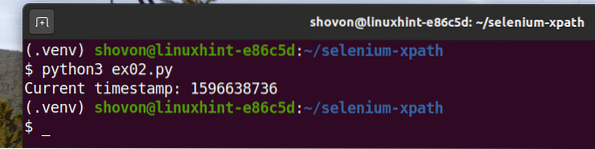
The prehliadač.find_element_by_xpath () a prehliadač.find_element () Na vyhľadanie a výber jedného prvku z webových stránok sa používajú metódy. Ak chcete nájsť a vybrať viac prvkov pomocou selektorov XPath, musíte použiť prehliadač.find_elements_by_xpath () alebo prehliadač.find_elements () metódy.
The prehliadač.find_elements_by_xpath () metóda má rovnaký argument ako prehliadač.find_element_by_xpath () metóda.
The prehliadač.find_elements () metóda má rovnaké argumenty ako prehliadač.find_element () metóda.
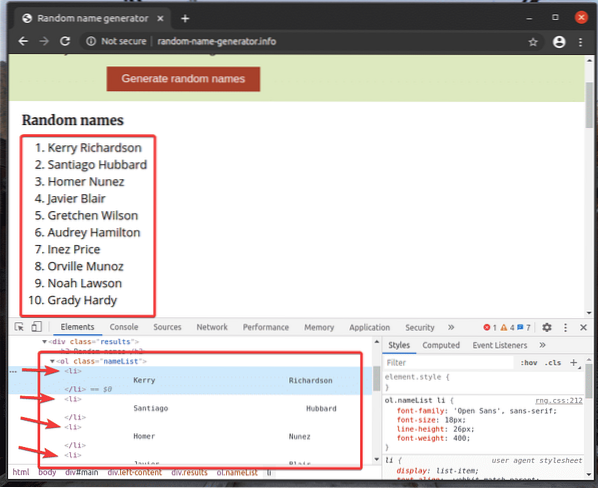
Pozrime sa na príklad extrakcie zoznamu mien pomocou selektora XPath z generátor náhodných mien.Info s knižnicou Selenium Python.
Neusporiadaný zoznam (ol značka) má 10 li značky vnútri každej, ktorá obsahuje náhodné meno. XPath vyberte všetky li značky vo vnútri ol značka v tomto prípade je // * [@ id = ”main”] / div [3] / div [2] / ol // li
Prejdime si príklad výberu viacerých prvkov z webovej stránky pomocou selektorov XPath.
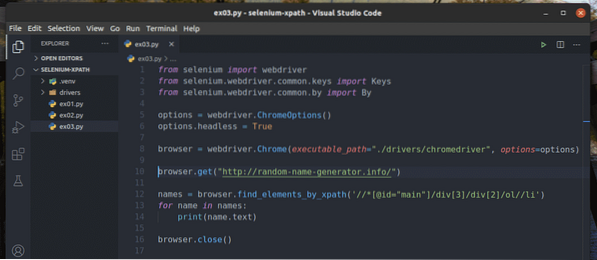
Vytvorte nový skript v jazyku Python ex03.py a zadajte do neho nasledujúce riadky kódov.
z webového ovládača na selén na importzo selénu.webdriver.bežné.kľúče na import kľúčov
zo selénu.webdriver.bežné.importom do
options = webdriver.ChromeOptions ()
možnosti.bezhlavý = Pravda
prehliadač = webdriver.Chrome (executable_path = "./ drivers / chromedriver ",
možnosti = možnosti)
prehliadač.get ("http: // generátor náhodných mien.Info/")
mená = prehliadač.find_elements_by_xpath ('
// * [@ id = "main"] / div [3] / div [2] / ol // li ')
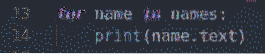
pre meno v menách:
tlač (meno.text)
prehliadač.Zavrieť()
Po dokončení uložte súbor ex03.py Skript v jazyku Python.
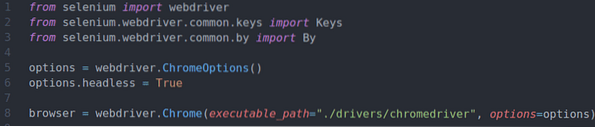
Riadok 1-8 je rovnaký ako v ex01.py Skript v jazyku Python. Takže ich tu už nebudem vysvetľovať.
Riadok 10 informuje prehliadač, aby načítal generátor náhodných mien webových stránok.Info.

Riadok 12 vyberie zoznam mien pomocou prehliadač.find_elements_by_xpath () metóda. Táto metóda využíva selektor XPath // * [@ id = ”main”] / div [3] / div [2] / ol // li vyhľadať zoznam mien. Potom sa zoznam mien uloží do priečinka mien premenná.

V riadkoch 13 a 14 sa a pre slučka sa používa na iteráciu cez mien zoznam a vytlačte mená na konzolu.
Riadok 16 zavrie prehliadač.

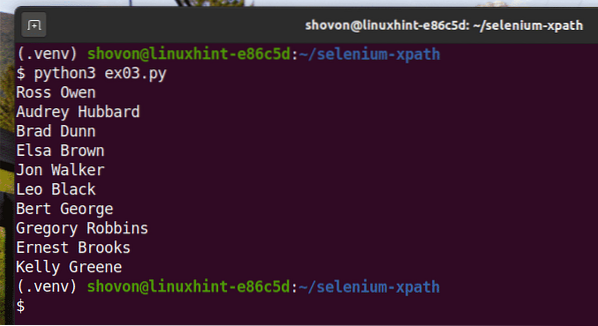
Spustite skript v jazyku Python ex03.py nasledovne:
$ python3 ex03.py
Ako vidíte, mená sú extrahované z webovej stránky a vytlačené na konzole.
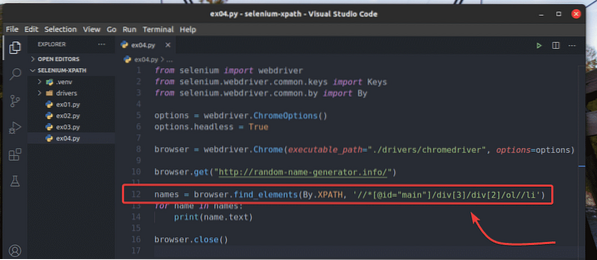
Namiesto použitia prehliadač.find_elements_by_xpath () metódou, môžete použiť aj prehliadač.find_elements () metóda ako predtým. Prvý argument tejto metódy je Autor:.XPATH, a druhým argumentom je selektor XPath.
Experimentovať s prehliadač.find_elements () metódou, vytvorte nový skript v jazyku Python ex04.py, skopírujte všetky kódy z ex03.py do ex04.py, a zmeňte riadok 12, ako je vyznačené na snímke obrazovky nižšie.
Mali by ste dosiahnuť rovnaký výsledok ako predtým.
$ python3 ex04.py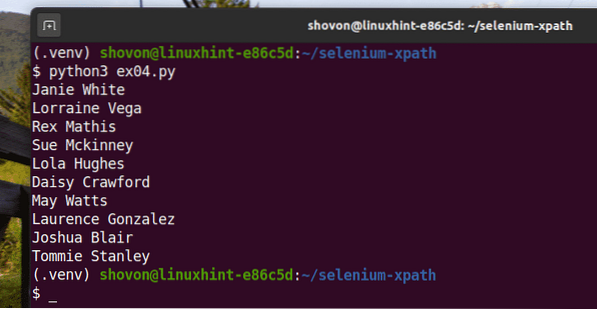
Základy selektora XPath:
Nástroj pre vývojárov prehliadača Firefox alebo webového prehliadača Google Chrome automaticky generuje selektor XPath. Ale tieto selektory XPath niekedy nie sú pre váš projekt postačujúce. V takom prípade musíte vedieť, čo určitý selektor XPath robí pri zostavovaní vášho selektora XPath. V tejto časti vám ukážem základy selektorov XPath. Potom by ste mali byť schopní zostaviť si vlastný selektor XPath.
Vytvorte nový adresár www / v adresári projektu nasledovne:
$ mkdir -v www
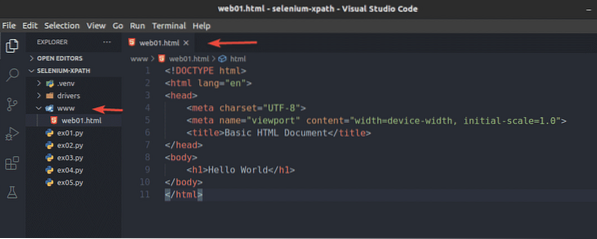
Vytvorte nový súbor web01.html v www / adresár a do tohto súboru zadajte nasledujúce riadky.
Ahoj svet
Po dokončení uložte súbor web01.html spis.
Spustite jednoduchý server HTTP na porte 8080 pomocou nasledujúceho príkazu:
$ python3 -m http.server - adresár www / 8080
Mal by sa spustiť server HTTP.
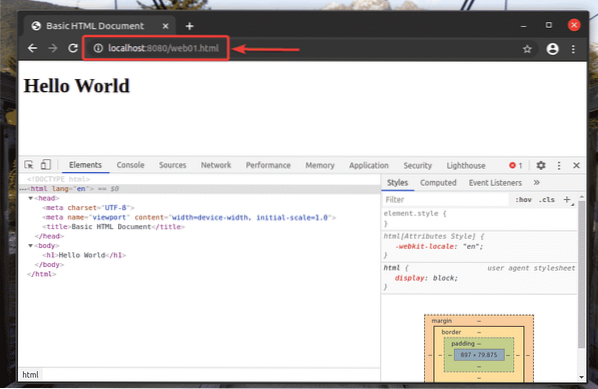
Mali by ste mať prístup k web01.html súbor pomocou adresy URL http: // localhost: 8080 / web01.html, ako vidíte na snímke obrazovky nižšie.
Pri otvorenom prehliadači Firefox alebo Chrome Developer Tool stlačte
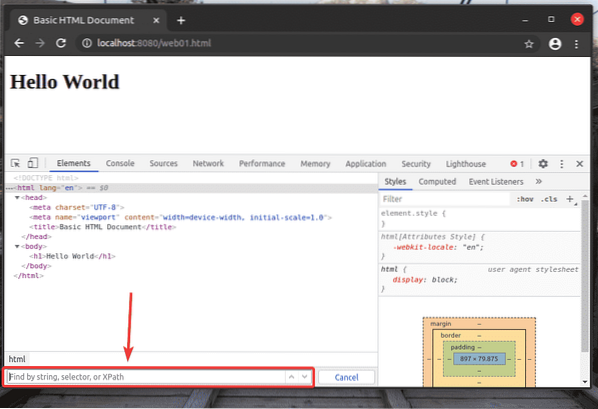
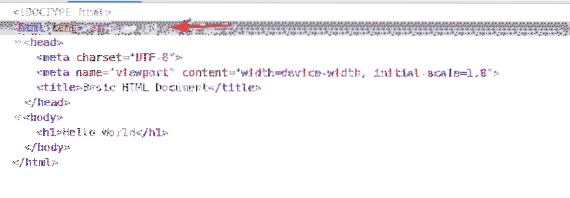
Selektor XPath začína na lomka (/) väčšinu času. Je to ako strom adresárov systému Linux. The / je koreňom všetkých prvkov na webovej stránke.
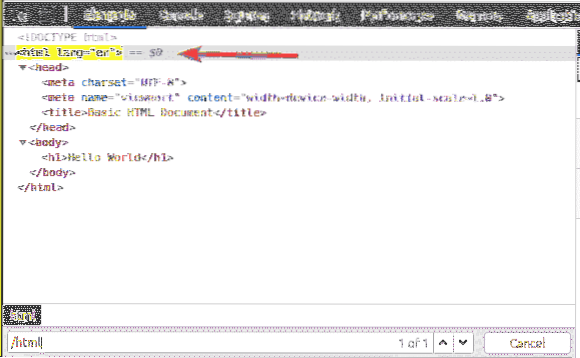
Prvým prvkom je html. Selektor XPath / html vyberie celú html značka.
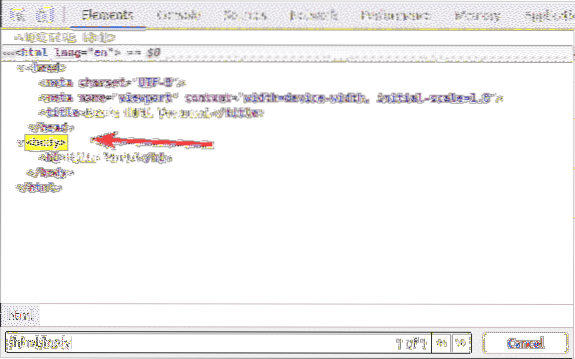
Vnútri html tag, máme a telo značka. The telo tag je možné zvoliť selektorom XPath / html / telo
The h1 hlavička je vo vnútri telo značka. The h1 hlavičku je možné zvoliť selektorom XPath / html / body / h1
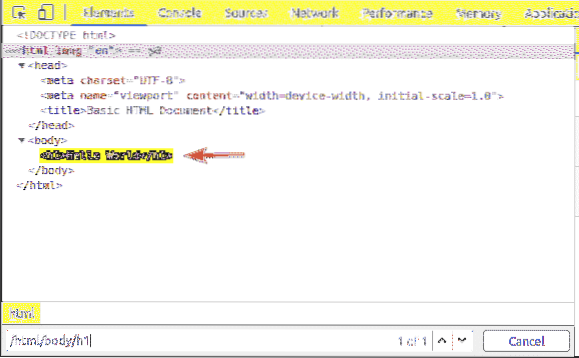
Tento typ selektora XPath sa nazýva selektor absolútnej cesty. V selektore absolútnej cesty musíte prejsť webovou stránkou z koreňa (/) stránky. Nevýhodou selektora absolútnej cesty je, že aj nepatrná zmena štruktúry webových stránok môže spôsobiť, že je selektor XPath neplatný. Riešením tohto problému je relatívny alebo čiastočný selektor XPath.
Ak chcete zistiť, ako funguje relatívna alebo čiastočná cesta, vytvorte nový súbor web02.html v www / adresár a zadajte do neho nasledujúce riadky kódov.
Ahoj svet
toto je správa
ahoj svet
Po dokončení uložte súbor web02.html súbor a načítajte ho do svojho webového prehliadača.
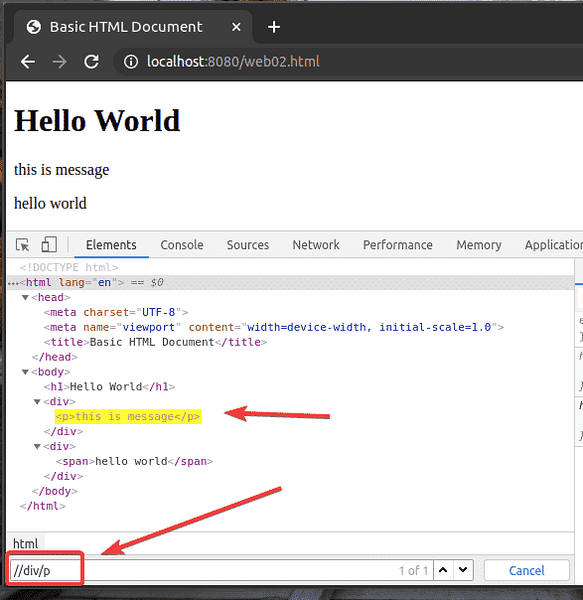
Ako vidíte, selektor XPath // div / p vyberie ikonu p značka vo vnútri div značka. Toto je príklad relatívneho selektora XPath.
Relatívny selektor XPath začína na //. Potom určíte štruktúru prvku, ktorý chcete vybrať. V tomto prípade, div / p.
Takže, // div / p znamená vyberte p prvok vo vnútri a div nezáleží na tom, čo bude pred ním.
Môžete tiež vybrať prvky podľa rôznych atribútov, napríklad id, trieda, typu, atď. pomocou selektora XPath. Pozrime sa, ako na to.
Vytvorte nový súbor web03.html v www / adresár a zadajte do neho nasledujúce riadky kódov.
Ahoj svet
toto je správa
toto je iná správa
nadpis 2
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Quibusdam
accendendi doloribus sapiente, molestias quos quae non nam incidunt quis delectus
facilis magni officiis alias neque atque fuga? Unde, aut natus?
Po dokončení uložte súbor web03.html súbor a načítajte ho do svojho webového prehliadača.
Povedzme, že chcete vybrať všetky možnosti div prvky, ktoré majú trieda názov kontajner1. Môžete to urobiť pomocou selektora XPath // div [@ class = 'container1']
Ako vidíte, mám 2 prvky, ktoré zodpovedajú selektoru XPath // div [@ class = 'container1']
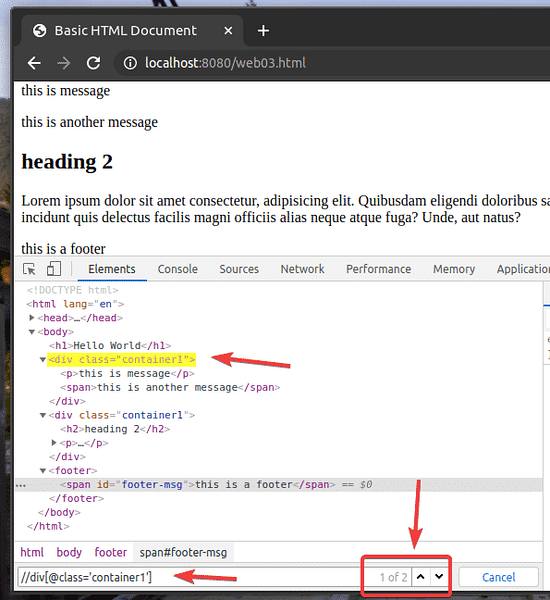
Ak chcete vybrať prvý div prvok s trieda názov kontajner1, pridať [1] na konci XPath vyberte, ako je znázornené na snímke obrazovky nižšie.
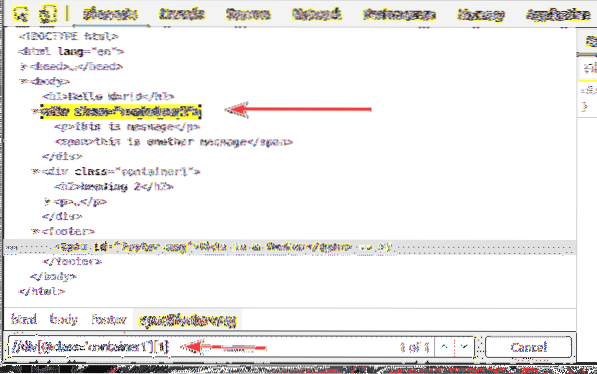
Rovnakým spôsobom môžete zvoliť druhú div prvok s trieda názov kontajner1 pomocou selektora XPath // div [@ class = 'container1'] [2]
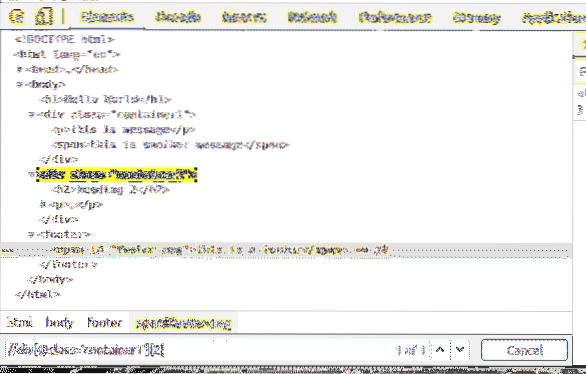
Prvky môžete vybrať pomocou id tiež.
Napríklad na výber prvku, ktorý má id z päta-správa, môžete použiť selektor XPath // * [@ id = 'footer-msg']
Tu je * predtým [@ id = 'footer-msg'] sa používa na výber ľubovoľného prvku bez ohľadu na jeho značku.
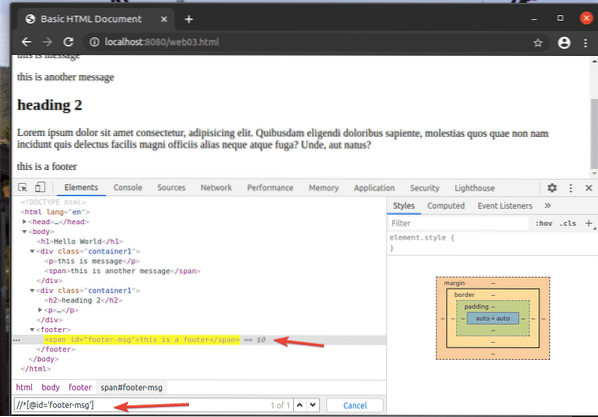
To sú základy selektora XPath. Teraz by ste mali byť schopní vytvoriť vlastný selektor XPath pre svoje projekty selénu.
Záver:
V tomto článku som vám ukázal, ako nájsť a vybrať prvky z webových stránok pomocou selektora XPath s knižnicou Selenium Python. Diskutoval som tiež o najbežnejších selektoroch XPath. Po prečítaní tohto článku by ste sa mali cítiť sebavedome pri výbere prvkov z webových stránok pomocou selektora XPath s knižnicou Selenium Python.


