- Na preformátovanie zdrojového kódu
- Na čistenie údajov
- Pre zjednodušenie výstupu z príkazového riadku
Ak hovoríme o úvodných bielych priestoroch, je ich možné ľahko zistiť tak, ako na začiatku textu. Nie je však ľahké spozorovať koncové biele medzery. To isté platí pre dvojité medzery, ktoré sú tiež niekedy ťažko rozpoznateľné. Všetko je náročnejšie, keď potrebujete z dokumentu, ktorý obsahuje tisíce riadkov, odstrániť všetky tie vedúce a koncové medzery.
Ak chcete z dokumentu odstrániť medzery, môžete použiť rôzne nástroje, ako sú awk, sed, cut a tr. V niektorých ďalších článkoch sme diskutovali o použití awk pri odstraňovaní medzery. V tomto článku budeme diskutovať o použití sedu na odstránenie bielych znakov z údajov.
Naučíte sa, ako používať sed na:
- Odstráňte všetky medzery
- Odstráňte úvodné biele medzery
- Odstráňte koncové medzery
- Odstráňte úvodné aj koncové biele medzery
- Viaceré medzery nahraďte jednou medzerou
Príkazy spustíme na Ubuntu 20.04 Focal Fossa. Rovnaké príkazy môžete spustiť aj na iných distribúciách Linuxu. Na spúšťanie príkazov použijeme predvolenú aplikáciu Ubuntu Terminal. Terminál otvoríte pomocou klávesovej skratky Ctrl + Alt + T.
Čo je Sed
Sed (skratka pre editor streamov) je veľmi výkonný a praktický nástroj v systéme Linux, ktorý nám umožňuje vykonávať základné manipulácie s textom na vstupných tokoch. Nie je to textový editor, ale pomáha manipulovať a filtrovať text. Prijíma vstupné toky a upravuje ich podľa pokynov používateľa a následne transformovaný text vytlačí na obrazovku.
So sed môžete:
- Vyberte text
- Hľadaný text
- Vložte text
- Nahradiť text
- Odstrániť text
Odstránenie medzery pomocou programu Sed
Na odstránenie medzery z textu použijeme nasledujúcu syntax:
s / REGEXP / náhrada / príznakyKde
- s /: je substitučný výraz
- REGEXP: je regulárny výraz, ktorý sa má zhodovať
- výmena: je náhradný reťazec
- vlajky: Označenie „g“ použijeme iba na globálne umožnenie substitúcie na každom riadku
Regulárne výrazy
Niektoré z regulárnych výrazov, ktoré tu použijeme, sú:
- ^ zápasy začiatok riadku
- $ zápasy koniec riadku
- + zhoduje sa s jedným alebo viacerými výskytmi predchádzajúceho znaku
- * zhoduje sa s nulovým alebo viac výskytmi predchádzajúceho znaku.
Na demonštračné účely použijeme nasledujúci vzorový súbor s názvom „testfile“.
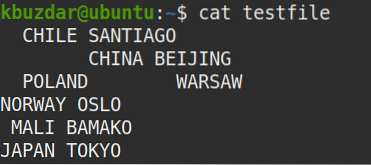
Zobraziť všetky medzery v súbore
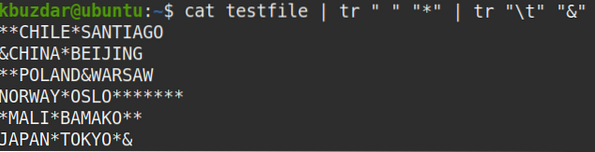
Ak chcete nájsť všetky medzery v súbore, prepojte výstup príkazu cat s príkazom tr takto:
$ testovací súbor mačiek | tr "" "*" | tr "\ t" "&"Tento príkaz nahradí všetky biele medzery vo vašom súbore symbolom (*), čo uľahčuje rozpoznanie všetkých bielych priestorov, či už ide o jednoduché, viacnásobné, vedúce alebo koncové biele medzery.
Na nasledujúcom obrázku je vidieť, že biele medzery sú nahradené symbolom *.
Odstrániť všetky medzery (vrátane medzier a tabulátorov)
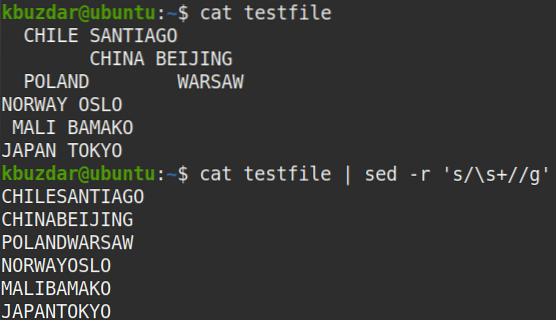
V niektorých prípadoch musíte z údajov odstrániť všetky medzery, t.j.e. úvodné, koncové a biele medzery medzi textami. Nasledujúci príkaz odstráni všetky medzery z „testovacieho súboru“.
$ testovací súbor mačiek | sed -r 's / \ s + // g'Poznámka: Sed nezmení vaše súbory, pokiaľ do nich neuložíte výstup.
Výkon:
Po spustení vyššie uvedeného príkazu sa objavil nasledujúci výstup, ktorý ukazuje, že z textu boli odstránené všetky medzery.
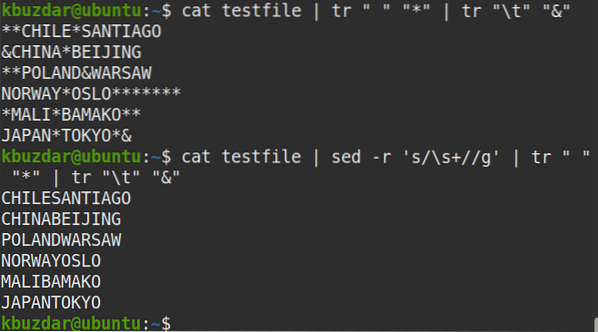
Pomocou nasledujúceho príkazu môžete tiež skontrolovať, či boli odstránené všetky medzery.
$ testovací súbor mačiek | sed -r 's / \ s + // g' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že neexistuje žiadny symbol (*), čo znamená, že boli odstránené všetky medzery.
Ak chcete odstrániť všetky medzery, ale iba z určitého riadku (povedzme riadok číslo 2), môžete použiť nasledujúci príkaz:
$ testovací súbor mačiek | sed -r '2s / \ s + // g'Odstrániť všetky vedúce medzery (vrátane medzier a tabulátorov)
Ak chcete odstrániť všetky medzery zo začiatku každého riadku (úvodné medzery), použite nasledujúci príkaz:
$ testovací súbor mačiek | sed 's / ^ [\ t] * //'Výkon:
Po vykonaní vyššie uvedeného príkazu sa objavil nasledujúci výstup, ktorý ukazuje, že z textu boli odstránené všetky medzery medzi riadkami.
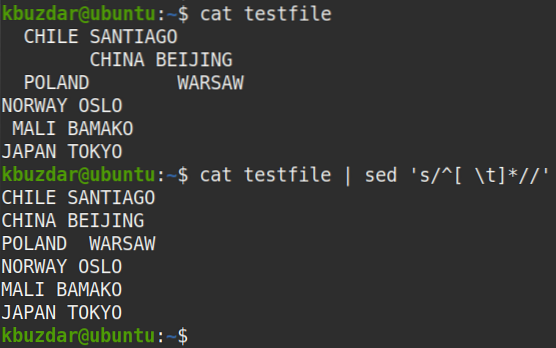
Pomocou nasledujúceho príkazu môžete tiež skontrolovať, či boli odstránené všetky medzery medzi sebou:
$ testovací súbor mačiek | sed 's / ^ [\ t] * //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na začiatku riadkov nie je žiadny symbol (*), ktorý overuje, že sú odstránené všetky vedúce biele medzery.
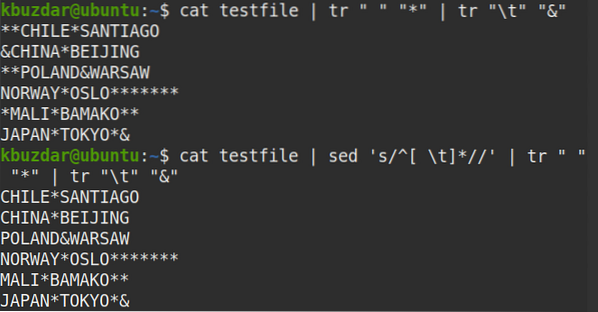
Ak chcete odstrániť medzery medzi sebou iba z konkrétneho riadku (povedzme riadok číslo 2), môžete použiť nasledujúci príkaz:
$ testovací súbor mačiek | sed '2s / ^ [\ t] * //'Odstrániť všetky koncové medzery (vrátane medzier a tabulátorov)
Ak chcete odstrániť všetky medzery z konca každého riadku (koncové medzery), použite nasledujúci príkaz:
$ testovací súbor mačiek | sed 's / [\ t] * $ //'Výkon:
Po vykonaní vyššie uvedeného príkazu sa objavil nasledujúci výstup, ktorý ukazuje, že z textu boli odstránené všetky koncové medzery.
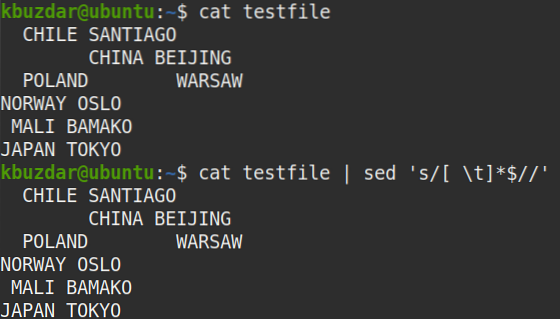
Pomocou nasledujúceho príkazu môžete tiež skontrolovať, či boli odstránené všetky koncové biele medzery.
$ testovací súbor mačiek | sed 's / [\ t] * $ //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na konci riadkov nie je žiadny symbol (*), ktorý overuje, že sú odstránené všetky koncové biele medzery.
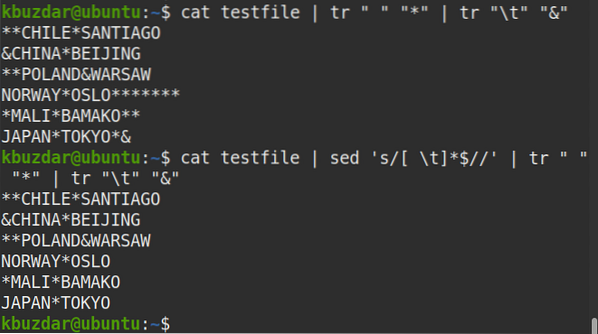
Ak chcete odstrániť koncové biele medzery iba z konkrétneho riadku (povedzme riadok číslo 2), môžete použiť nasledujúci príkaz:
$ testovací súbor mačiek | sed '2s / [\ t] * $ //'Odstráňte úvodné aj koncové biele medzery
Ak chcete odstrániť všetky medzery na začiatku a na konci každého riadku (t.j.e. úvodné aj koncové biele medzery), použite nasledujúci príkaz:
$ testovací súbor mačiek | sed 's / ^ [\ t] * //; s / [\ t] * $ //'Výkon:
Po vykonaní vyššie uvedeného príkazu sa objavil nasledujúci výstup, ktorý ukazuje, že z textu boli odstránené úvodné aj koncové biele medzery.
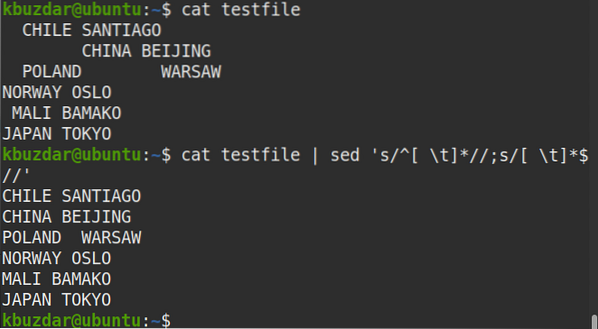
Pomocou nasledujúceho príkazu môžete tiež skontrolovať, či boli odstránené úvodné aj koncové biele medzery.
$ testovací súbor mačiek | sed 's / ^ [\ t] * //; s / [\ t] * $ //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na začiatku alebo na konci riadkov nie je žiadny symbol (*), ktorý by overoval odstránenie všetkých vedúcich a koncových medzier.
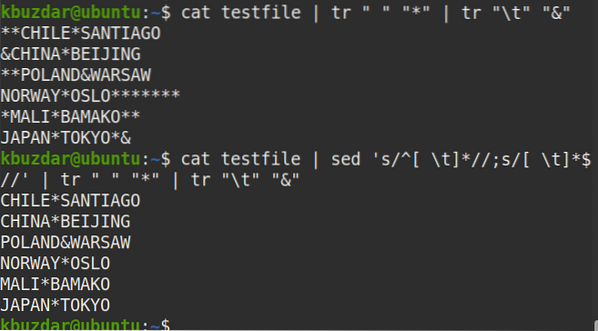
Ak chcete odstrániť úvodné aj koncové biele medzery iba z konkrétneho riadku (povedzme riadok číslo 2), môžete použiť nasledujúci príkaz:
$ testovací súbor mačiek | sed '2s / ^ [\ t] * //; 2s / [\ t] * $ //'Nahraďte viac medzery jedným prázdnym priestorom
V niektorých prípadoch je v súbore viac prázdnych miest na rovnakom mieste, ale potrebujete iba jeden prázdny priestor. Môžete to urobiť nahradením týchto viacerých medzier za jeden priestor pomocou sed.
Nasledujúci príkaz nahradí všetky viaceré medzery jedným prázdnym znakom z každého riadku v testovacom súbore.
$ testovací súbor mačiek | sed 's / [] \ + / / g'Výkon:
Po vykonaní vyššie uvedeného príkazu sa objavil nasledujúci výstup, ktorý ukazuje, že viaceré medzery boli nahradené jedným prázdnym znakom.
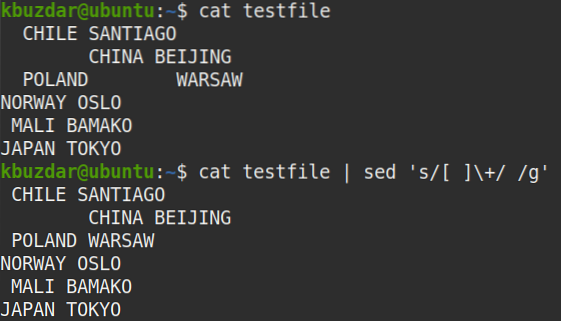
Pomocou nasledujúceho príkazu môžete tiež overiť, či sa viaceré medzery nahradia jedným prázdnym znakom:
$ testovací súbor mačiek | sed 's / [] \ + / / g' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte na každom mieste jeden symbol (*), ktorý overuje, že všetky výskyty viacerých medzier sú nahradené jedným bielym priestorom.
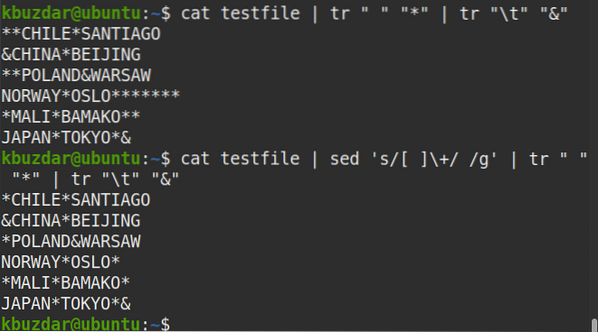
Toto bolo teda všetko o odstránení bielych priestorov z vašich údajov pomocou sed. V tomto článku ste sa naučili, ako používať sed na odstránenie všetkých bielych priestorov z vašich údajov, odstránenie iba úvodného alebo koncového bieleho priestoru a odstránenie úvodného aj posledného bieleho priestoru. Naučili ste sa tiež, ako nahradiť viac medzier jedným priestorom. Teraz bude pre vás ľahké odstrániť medzery zo súboru, ktorý obsahuje stovky alebo tisíce riadkov.


