Pandy .read_csv
O histórii a použití pandy pre knižnicu Python som už hovoril. pandy boli vyvinuté z dôvodu potreby efektívnej knižnice pre analýzu a manipuláciu s finančnými dátami pre Python. Na účely načítania údajov na analýzu a manipuláciu poskytujú pandy dve metódy, DataReader a read_csv. Prvý som tu zakryl. Posledná zmienka je predmetom tohto tutoriálu.
.read_csv
Existuje veľké množstvo bezplatných archívov údajov online, ktoré obsahujú informácie z rôznych oblastí. Niektoré z týchto zdrojov som zahrnul do sekcie odkazov nižšie. Pretože som tu demonštroval zabudované rozhrania API na efektívne získavanie finančných údajov, použijem v tomto návode iný zdroj údajov.
Údaje.gov ponúka obrovský výber bezplatných údajov o všetkom, od zmeny podnebia po U.S. výrobná štatistika. Stiahol som si dve sady údajov na použitie v tomto výučbe. Prvou je priemerná denná maximálna teplota pre okres Bay County na Floride. Tieto údaje boli stiahnuté z U.S. Sada nástrojov na odolnosť proti zmene klímy na obdobie rokov 1950 až do súčasnosti.
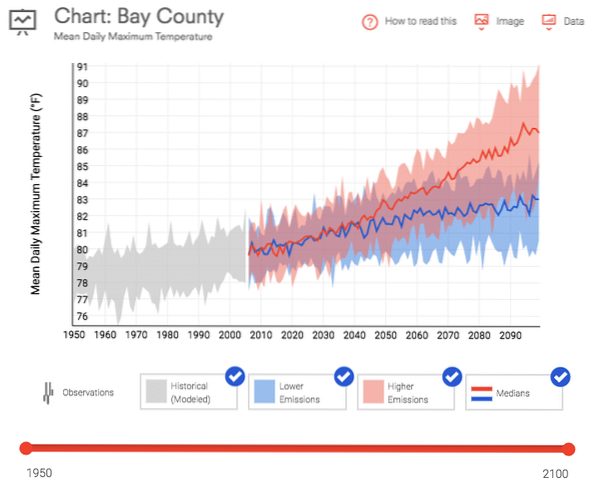
Druhým je prieskum komoditných tokov, ktorý meria spôsob a objem dovozu do krajiny počas päťročného obdobia.

Oba odkazy na tieto súbory údajov sú uvedené v časti s odkazmi nižšie. The .read_csv metóda, ako je zrejmé z názvu, načíta tieto informácie zo súboru CSV a vytvorí inštanciu a DataFrame z tohto súboru údajov.
Využitie
Kedykoľvek použijete externú knižnicu, musíte Pythonu povedať, že je potrebné ho importovať. Nižšie je uvedený riadok kódu, ktorý importuje knižnicu pandas.
importovať pandy ako pdZákladné použitie .read_csv metóda je uvedená nižšie. Toto vytvára inštancie a vyplňuje a DataFrame df s informáciami v súbore CSV.
df = pd.read_csv ('12005-year-hist-obs-tasmax.csv ')Pridaním ďalších pár riadkov môžeme skontrolovať prvých a posledných 5 riadkov z novovytvoreného údajového rámca.
df = pd.read_csv ('12005-year-hist-obs-tasmax.csv ')tlač (porov.hlava (5))
tlač (porov.chvost (5))

Tento kód načítal stĺpec pre rok, priemernú dennú teplotu v stupňoch Celzia (tasmax), a vytvoril indexačnú schému založenú na 1, ktorá sa zvyšuje pre každý riadok údajov. Je tiež dôležité poznamenať, že hlavičky sú vyplnené zo súboru. Pri základnom použití vyššie uvedenej metódy sa predpokladá, že hlavičky sa nachádzajú v prvom riadku súboru CSV. To je možné zmeniť odovzdaním inej sady parametrov metóde.
Parametre
Poskytla som odkaz na pandy .read_csv dokumentáciu v odkazoch nižšie. Existuje niekoľko parametrov, ktoré možno použiť na zmenu spôsobu čítania a formátovania údajov v priečinku DataFrame.

Existuje pomerne veľa parametrov pre .read_csv metóda. Väčšina z nich nie je nevyhnutná, pretože väčšina súborov údajov, ktoré stiahnete, bude mať štandardný formát. To sú stĺpce v prvom riadku a oddeľovač čiarky.
Existuje niekoľko parametrov, ktoré v tutoriále zvýrazním, pretože môžu byť užitočné. Podrobnejší prieskum je možné získať na stránke dokumentácie.
index_col
index_col je parameter, ktorým možno označiť stĺpec, ktorý obsahuje index. Niektoré súbory môžu obsahovať index a niektoré nie. V našej prvej množine údajov som nechal python vytvoriť index. Toto je štandard .read_csv správanie.
V našom druhom súbore údajov je zahrnutý index. Nasledujúci kód načíta súbor DataFrame s údajmi v súbore CSV, ale namiesto vytvorenia prírastkového celočíselného indexu použije stĺpec SHPMT_ID zahrnutý v množine údajov.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ')tlač (porov.hlava (5))
tlač (porov.chvost (5))
Aj keď tento súbor údajov používa pre index rovnakú schému, iné súbory údajov môžu mať užitočnejší index.
nrow, skiprows, usecols
Pri veľkých množinách údajov možno budete chcieť načítať iba časti údajov. The nrow, skoky, a pouzivane klipy parametre vám umožnia rozdeliť údaje obsiahnuté v súbore.
df = pd.read_csv ('cfs_2012_pumf_csv.txt ', index_col =' SHIPMT_ID ', nrows = 50)tlač (porov.hlava (5))
tlač (porov.chvost (5))
Pridaním nrow parameter s celočíselnou hodnotou 50, .tail call teraz vráti linky až na 50. Zvyšok údajov v súbore sa neimportuje.
tlač (porov.hlava (5))
tlač (porov.chvost (5))
Pridaním skoky parameter, náš .hlava col v údajoch nezobrazuje počiatočný index 1001. Pretože sme preskočili riadok hlavičky, nové údaje stratili hlavičku a index na základe údajov súboru. V niektorých prípadoch môže byť lepšie rozdeliť údaje do a DataFrame skôr ako pred načítaním údajov.

The pouzivane klipy je užitočný parameter, ktorý umožňuje importovať iba podmnožinu údajov podľa stĺpcov. Môže sa mu odovzdať nultý index alebo zoznam reťazcov s názvami stĺpcov. Nasledujúci kód som použil na import prvých štyroch stĺpcov do nášho nového DataFrame.
df = pd.read_csv ('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3])
tlač (porov.hlava (5))
tlač (porov.chvost (5))
Z nášho nového .hlava zavolajte, náš DataFrame teraz obsahuje iba prvé štyri stĺpce z množiny údajov.
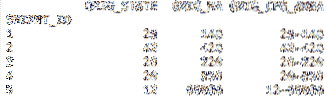
motor
Jedným z posledných parametrov, o ktorých si myslím, že by sa v niektorých súboroch údajov mohli hodiť, je motor parameter. Môžete použiť buď motor založený na C, alebo kód založený na Pythone. Motor C bude prirodzene rýchlejší. To je dôležité, ak importujete veľké množiny údajov. Výhodou syntaktickej analýzy Pythonu je sada bohatšia na funkcie. Táto výhoda môže znamenať menej, ak načítate veľké dáta do pamäte.
df = pd.read_csv ('cfs_2012_pumf_csv.TXT',index_col = 'SHIPMT_ID', engine = 'c')
tlač (porov.hlava (5))
tlač (porov.chvost (5))
Nasleduj
Existuje niekoľko ďalších parametrov, ktoré môžu rozšíriť predvolené správanie súboru .read_csv metóda. Dajú sa nájsť na stránke dokumentov, na ktorú som odkazoval nižšie. .read_csv je užitočná metóda na načítanie súborov údajov do pandy na analýzu údajov. Pretože veľa bezplatných súborov údajov na internete nemá API, bude to najužitočnejšie pre aplikácie mimo finančných údajov, kde sú k dispozícii robustné API na import údajov do pandy.
Referencie
https: // pandy.pydata.org / pandas-docs / stable / generované / pandy.read_csv.html
https: // www.údaje.vláda /
https: // sada nástrojov.podnebie.gov / # explorer podnebia
https: // www.sčítanie ľudu.gov / econ / cfs / pums.html