Príklad 1: Vyhľadávanie konkrétneho reťazca v súbore
Toto je najbežnejšie použitie príkazu egrep. Robíte to tak, že zadáte reťazec, ktorý chcete vyhľadať, a názov súboru, v ktorom chcete daný reťazec vyhľadať. Výsledok potom zobrazí celý riadok obsahujúci hľadaný reťazec.
Syntax:
$ egrep „vyhľadávací_reťazec“ názov súboruPríklad:
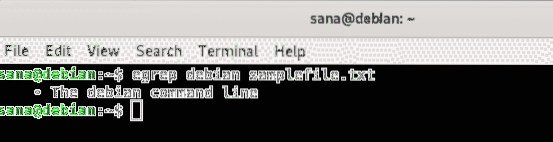
$ egrep debian samplefile.TXTV tomto príklade som hľadal slovo „debian“ v zadanom textovom súbore. Môžete vidieť, ako výsledky zobrazujú celý riadok, ktorý obsahuje slovo „debian“:
Príklad 2: Vyhľadávanie konkrétneho reťazca vo viacerých súboroch
Pomocou príkazu egrep môžete vyhľadať reťazec medzi viacerými súbormi nachádzajúcimi sa v rovnakom adresári. Musíte byť len trochu konkrétnejší v poskytovaní „vzoru“ pre hľadané súbory. To bude jasnejšie na príklade, ktorý uvedieme.
Syntax:
$ egrep "reťazec hľadania" vzor_súboruPríklad:
Tu budeme hľadať slovo „debian“ vo všetkých jazykoch .súbory txt zadaním vzoru názvu súboru takto:
$ egrep „debian“ *.TXT
Príkaz vytlačil všetky riadky spolu s názvami súborov, ktoré obsahujú slovo „debian“, zo všetkých súborov .txt súbory v aktuálnom adresári.
Príklad 3: Rekurzívne prehľadanie reťazca v celom adresári
Ak chcete vyhľadať reťazec vo všetkých súboroch z adresára a jeho podadresárov, môžete to urobiť pomocou príznaku -r s príkazom egrep.
Syntax:
$ egrep -r "vyhľadávací_reťazec" *Príklad:
V tomto príklade hľadám slovo „sample“ v súboroch celého aktuálneho adresára (Downloads).
$ egrep -r "sample" *
Výsledky obsahujú všetky riadky spolu s názvami súborov, ktoré obsahujú slovo „sample“ zo všetkých súborov v adresári Downloads a jeho podadresároch.
Príklad 4: Vykonanie vyhľadávania bez rozlišovania malých a veľkých písmen
Pomocou príznaku -i môžete pomocou príkazu egrep vytlačiť výsledky na základe vyhľadávacieho reťazca bez obáv z prípadu.
Syntax:
$ egrep -i „hľadaný_reťazec“ názov súboruPríklad:
Tu hľadám slovo „debian“ a chcem, aby výsledky zobrazili všetky riadky zo súboru, ktoré obsahujú slovo „debian“ alebo „Debian, bez ohľadu na jeho prípad“.
$ egrep -i „hľadaný_reťazec“ názov súboru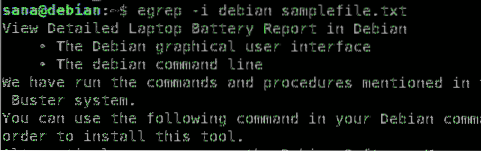
Môžete vidieť, ako mi príznak -i pomohol pri načítaní všetkých riadkov, ktoré obsahujú vyhľadávací reťazec, pomocou vyhľadávania „necitlivého na malé a veľké písmená“.
Príklad 5: Hľadanie reťazca ako celého slova, a nie ako podreťazca
Keď bežne hľadáte reťazec cez egrep, vytlačí sa všetky slová, ktoré obsahujú reťazec, ako podreťazec. Napríklad vyhľadanie reťazca „on“ vytlačí všetky slová obsahujúce reťazec „on“ ako „on“, „only“, „monitor“, „clone“ atď. Ak chcete, aby výsledky zobrazovali iba slovo „zapnuté“ ako celé slovo a nie ako podreťazec, môžete použiť príznak -w s egrep.
Syntax:
$ egrep -w názov_vyhľadávacieho_reťazcaPríklad:
Tu hľadám reťazec „on“ vo vzorovom súbore:
$ egrep -i „na“ vzorovom súbore.TXT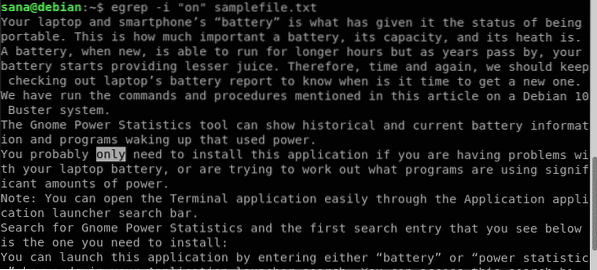
Na výstupe vyššie vidíte, že obsahuje aj slovo „iba“. To však nie je to, čo chcem, pretože výlučne hľadám slovo „on“. Toto je teda príkaz, ktorý použijem namiesto toho:
$ egrep -iw „na“ vzorovom súbore.TXT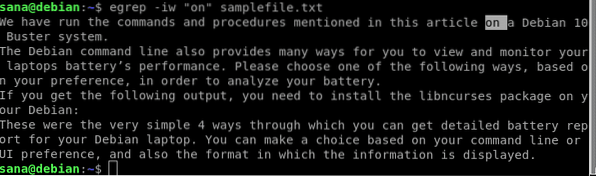
Moje výsledky vyhľadávania teraz zahŕňajú iba riadky, ktoré obsahujú slovo „zapnuté“ ako celé slovo.
Príklad 6: Tlač iba názvov súborov, ktoré obsahujú reťazec
Niekedy chceme iba načítať názvy súborov, ktoré obsahujú konkrétny reťazec, a nie tlačiť riadky, ktoré ho obsahujú. To je možné vykonať pomocou príznaku -l (malé L) pomocou príkazu egrep.
Syntax:
$ egrep -l "reťazec hľadania" vzor_súboruPríklad:
Tu hľadám reťazec „sample“ vo všetkých .Súbory txt v aktuálnom adresári:
$ egrep -l vzorka *.TXT
Z výsledkov vyhľadávania sa vytlačí iba názov súborov, ktoré obsahujú zadaný reťazec.
Príklad 7: Tlač iba hľadaného reťazca zo súboru
Namiesto toho, aby ste vytlačili celý riadok, ktorý obsahuje hľadaný reťazec, môžete na vytlačenie samotného reťazca použiť príkaz egrep. Reťazec sa vytlačí koľkokrát sa objaví v zadanom súbore.
Syntax:
$ egrep -o "vyhľadávací_reťazec" názov súboruPríklad:
V tomto príklade hľadám vo svojom súbore slovo „Toto“.
$ egrep -o Tento ukážkový súbor_.TXT
Poznámka: Toto použitie príkazu sa hodí, keď hľadáte reťazec na základe vzoru regulárneho výrazu. Regulárne výrazy si podrobne vysvetlíme v jednom z nasledujúcich príkladov.
Príklad 8: Zobrazenie n počtu riadkov pred, za alebo okolo vyhľadávacieho reťazca
Niekedy je veľmi dôležité poznať kontext v súbore, kde sa používa konkrétny reťazec. Egrep sa hodí v tom zmysle, že ho možno použiť na zobrazenie riadku obsahujúceho hľadaný reťazec a tiež konkrétneho počtu riadkov pred, za a okolo neho.
Toto je ukážkový textový súbor, ktorý budem používať na vysvetlenie nasledujúcich príkladov:

N počet riadkov Za hľadaným reťazcom:
Použitím príznaku A nasledujúcim spôsobom sa zobrazí riadok obsahujúci hľadaný reťazec a N počet riadkov za ním:
$ egrep -APríklad:
$ egrep -A 2 „sample“ samplefile.TXT
N počet riadkov pred hľadaným reťazcom:
Použitím príznaku B nasledujúcim spôsobom sa zobrazí riadok obsahujúci vyhľadávací reťazec a N počet riadkov pred ním:
$ egrep -BPríklad:
$ egrep -B 2 „sample“ samplefile.TXT
N počet riadkov pred hľadaným reťazcom:
Použitím príznaku C nasledujúcim spôsobom sa zobrazí riadok obsahujúci hľadaný reťazec a N počet riadkov pred a za:
$ egrep -CPríklad:
$ egrep -C 2 „sample“ samplefile.TXT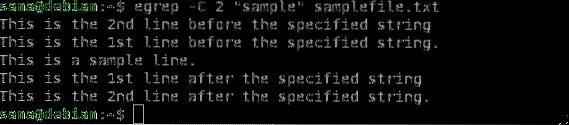
Príklad 9: Zhoda regulárneho výrazu v súboroch
Príkaz egrep sa stáva výkonnejším, keď hľadáte regulárne výrazy namiesto pevných vyhľadávacích reťazcov v súbore.
Syntax:
$ egrep "RegularExpressions" názov súboruVysvetlíme vám, ako môžete používať regulárne výrazy pri vyhľadávaní egrep:
| Operátor opakovania | Použite |
| ? | Predchádzajúca položka predtým ? je voliteľné a zhoduje sa maximálne raz
|
| * | Predchádzajúca položka pred * bude priradená nula alebo viackrát |
| + | Predchádzajúca položka pred + sa zhoduje jeden alebo viackrát |
| n | Predchádzajúca položka je n-krát presne zhodovaná. |
| n, | Predchádzajúca položka je priradená n alebo viackrát |
| , m | Predchádzajúca položka sa zhoduje maximálne m krát |
| n, m | Predchádzajúca položka je priradená najmenej n-krát, ale najviac m-krát |
Príklad:
V nasledujúcom príklade sa zhodujú riadky obsahujúce nasledujúci výraz:
začínajúce na „Gnome“ a končiace na „programy“

Príklad 10: Zvýraznenie hľadaného reťazca
Keď nastavíte premennú prostredia GREP_OPTIONS, ako je uvedené nižšie, získate výstup so zvýrazneným vyhľadávacím reťazcom / vzorom vo výsledkoch:
$ sudo export GREP_OPTIONS = '- color = auto' GREP_COLOR = '100; 8'Potom môžete reťazec vyhľadať ľubovoľným spôsobom, ktorý sme opísali v príkladoch tohto článku.
Príklad 11: Vykonanie inverzného vyhľadávania v súbore
Invertným vyhľadávaním rozumieme, že príkaz egrep vytlačí všetko v súbore, okrem riadkov, ktoré obsahujú vyhľadávací reťazec. Nasledujúci vzorový súbor použijeme na vysvetlenie inverzného vyhľadávania cez egrep. Obsah súboru sme vytlačili pomocou príkazu cat:
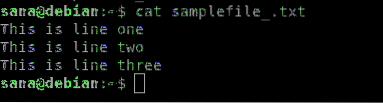
Syntax:
$ egrep -v "hľadaný_reťazec" názov súboruPríklad:
Z ukážkového súboru, ktorý sme spomenuli, chceme na výstupe vynechať riadok obsahujúci slovo „two“, preto použijeme nasledujúci príkaz:
$ egrep -v „two“ samplefile_.TXT
Môžete vidieť, ako výstup obsahuje všetko zo vzorového súboru okrem druhého riadku, ktorý obsahoval vyhľadávací reťazec „dva“.
Príklad 12: Vykonanie inverzného vyhľadávania na základe viacerých kritérií / vyhľadávacieho vzoru
S príznakom -v môžete tiež vykonať príkaz egrep na vykonanie inverzného vyhľadávania na základe viac ako jedného vyhľadávacieho reťazca / vzoru.
Na vysvetlenie tohto scenára použijeme rovnaký vzorový súbor, aký sme uviedli v príklade 11.
Syntax:
$ egrep -v -e „reťazec_vyhľadávania“ / „vzor“ -e „reťazec_vyhľadávania“ / „vzor“… názov súboru
Príklad:
Z ukážkového súboru, ktorý sme spomenuli, chceme vynechať riadok (y) obsahujúce vo výstupe slová „jeden“ a „dva“, preto použijeme nasledujúci príkaz:
$ egrep -v -e „jeden“ -e „dva“ ukážkový súbor_.TXTPoskytli sme dve slová, ktoré treba pomocou príznaku -e vynechať, preto sa výstup zobrazí nasledovne:

Príklad 13: Tlač počtu riadkov, ktoré sa zhodujú s hľadaným reťazcom
Namiesto vytlačenia hľadaného reťazca zo súboru alebo riadkov, ktoré ho obsahujú, môžete pomocou príkazu egrep spočítať a vytlačiť počet riadkov zhodných s reťazcom. Tento počet je možné načítať pomocou príznaku -c príkazom egrep.
Syntax:
$ egrep -c "hľadaný_reťazec" názov súboruPríklad:
V tomto príklade použijeme príznak -c na spočítanie počtu riadkov, ktoré obsahujú slovo „This“ v našom vzorovom súbore:
$ egrep -c „Tento“ názov súboru
Môžete tu tiež použiť funkciu invertného vyhľadávania na spočítanie a tlač počtu riadkov, ktoré neobsahujú hľadaný reťazec:
$ grep -v -c "hľadaný_reťazec" názov súboru
Príklad 14: Zobrazenie čísla riadku, kde sa reťazec zhoduje
Pomocou príznaku -n môžete príkazom egrep vytlačiť zhodný riadok spolu s číslom riadku, ktorý obsahuje hľadaný reťazec.
Syntax:
$ grep -n „hľadaný_reťazec“ názov súboruPríklad:
$ grep -n „Tento“ ukážkový súbor_.TXT
Môžete vidieť, ako sa čísla riadkov zobrazujú oproti výsledkom vyhľadávania.
Príklad 15: Zobrazenie pozície v súbore, kde sa zhoduje hľadaný reťazec
Ak chcete poznať pozíciu v súbore, kde existuje hľadaný reťazec, môžete použiť príkaz -b s príkazom egrep.
$ grep -o -b „hľadaný_reťazec“ názov súboruPríklad:
$ grep -o -b „Tento“ ukážkový súbor_.TXT
Výsledky vyhľadávania vytlačia posunutie bajtov súboru, v ktorom existuje hľadané slovo.Toto bolo podrobné použitie príkazu egrep. Pomocou kombinácie príznakov vysvetlených v tomto článku môžete vo svojich súboroch vykonávať zmysluplnejšie a komplexnejšie vyhľadávanie.


