Prečo je potrebný Lucene?
Vyhľadávanie je jednou z najbežnejších operácií, ktoré vykonávame niekoľkokrát denne. Toto vyhľadávanie môže byť na viacerých webových stránkach, ktoré existujú na webe alebo v hudobnej aplikácii alebo v úložisku kódov alebo v kombinácii všetkých týchto. Jeden by si mohol myslieť, že jednoduchá relačná databáza môže tiež podporovať vyhľadávanie. Toto je správne. Databázy ako MySQL podporujú fulltextové vyhľadávanie. Čo však s webovou alebo hudobnou aplikáciou alebo archívom kódov alebo s kombináciou všetkých týchto možností? Databáza nemôže ukladať tieto údaje do svojich stĺpcov. Aj keby to tak bolo, spustenie tohto veľkého hľadania bude trvať neprijateľne dlho.
Fulltextový vyhľadávací modul je schopný spustiť vyhľadávací dopyt na miliónoch súborov naraz. Rýchlosť, akou sú dnes dáta v aplikácii ukladané, sú obrovské. Spustenie fulltextového vyhľadávania na takomto objeme dát je ťažká úloha. Je to tak preto, lebo informácie, ktoré potrebujeme, môžu existovať v jednom súbore z miliárd súborov uchovávaných na webe.
Ako funguje Lucene?
Zrejmá otázka, ktorá by vás mala napadnúť, je, ako je Lucene taký rýchly pri spúšťaní fulltextových vyhľadávacích dotazov? Odpoveď na to, samozrejme, je pomocou indexov, ktoré vytvára. Namiesto vytvorenia klasického indexu však Lucene využíva Invertované indexy.
V klasickom indexe zhromažďujeme pre každý dokument úplný zoznam slov alebo výrazov, ktoré dokument obsahuje. V obrátenom indexe pre každé slovo vo všetkých dokumentoch ukladáme, aký dokument a umiestnenie tohto slova / výrazu nájdete na. Jedná sa o vysoko štandardný algoritmus, vďaka ktorému je vyhľadávanie veľmi jednoduché. Zvážte nasledujúci príklad vytvorenia klasického indexu:
Doc1 -> "This", "is", "simple", "Lucene", "sample", "classic", "inverted", "index"Doc2 -> "Spustené", "Elasticsearch", "Ubuntu", "Aktualizovať"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Spring", "Boot"
Ak použijeme inverzný index, budeme mať indexy ako:
This -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Rámec -> (32, 11)
Invertované indexy sa udržiavajú oveľa ľahšie. Predpokladajme, že ak chceme nájsť Apache v mojich podmienkach, budem mať okamžité odpovede s Invertovanými indexmi, zatiaľ čo pri klasickom vyhľadávaní bude prebiehať kompletný dokument, ktorý by nebolo možné spustiť v scenároch v reálnom čase.
Lucene workflow
Predtým, ako bude môcť Lucene skutočne vyhľadávať údaje, je potrebné vykonať určité kroky. Pre lepšie pochopenie si predstavíme tieto kroky:
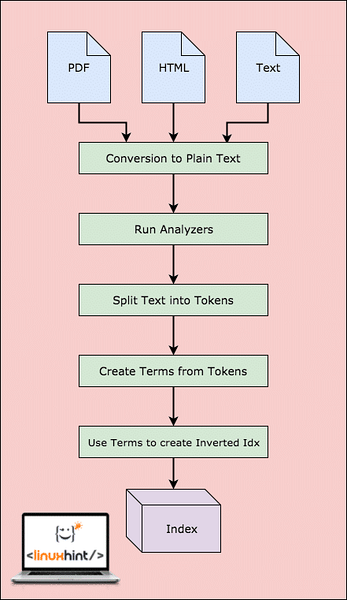
Lucene Workflow
Ako je znázornené na diagrame, v Lucene sa deje toto:
- Lucene podáva dokumenty a ďalšie zdroje údajov
- Pre každý dokument Lucene najskôr prevedie tieto údaje na obyčajný text a potom analyzátory skonvertujú tento zdroj na obyčajný text
- Pre každý výraz v obyčajnom texte sa vytvárajú obrátené indexy
- Indexy sú pripravené na vyhľadávanie
Vďaka tomuto pracovnému postupu je Lucene veľmi silný fulltextový vyhľadávací nástroj. Toto je ale jediná časť, ktorú Lucene spĺňa. Musíme si prácu vykonať sami. Pozrime sa na potrebné komponenty indexovania.
Lucene Components
V tejto časti si popíšeme základné komponenty a základné triedy Lucene používané na vytváranie indexov:
- Adresáre: Register Lucene ukladá údaje v bežných adresároch súborového systému alebo v pamäti, ak potrebujete vyšší výkon. Je to úplne voľba aplikácií na ukladanie údajov, kamkoľvek chcete, databázy, pamäte RAM alebo disku.
- Dokumenty: Údaje, ktoré napájame do motora Lucene, je potrebné previesť do obyčajného textu. Aby sme to dosiahli, urobíme objekt Document, ktorý predstavuje tento zdroj údajov. Neskôr, keď spustíme vyhľadávací dopyt, ako výsledok dostaneme zoznam objektov dokumentu, ktoré vyhovujú zadanému dotazu.
- Polia: Dokumenty sú vyplnené kolekciou polí. Pole je jednoducho pár (meno, hodnota) položky. Pri vytváraní nového objektu Dokumentu ho teda musíme vyplniť týmto druhom spárovaných údajov. Keď je pole nepriamo indexované, hodnota poľa je tokenizovaná a je k dispozícii na vyhľadávanie. Teraz, keď používame Fields, nie je dôležité ukladať skutočný pár, ale iba obrátený indexovaný. Týmto spôsobom môžeme rozhodnúť, ktoré dáta sú iba prehľadávateľné a nie je dôležité ich ukladať. Pozrime sa na príklad tu:

Indexovanie polí
Vo vyššie uvedenej tabuľke sme sa rozhodli uložiť niektoré polia a iné nie sú uložené. Pole tela nie je uložené, ale indexované. To znamená, že e-mail sa vráti ako výsledok, keď sa spustí dopyt na jednu z podmienok pre obsah tela.
- Podmienky: Termíny predstavujú slovo z textu. Pojmy sa získavajú z analýzy a tokenizácie hodnôt Fields Výraz je najmenšia jednotka, na ktorej je spustené vyhľadávanie.
- Analyzátory: Analyzátor je najdôležitejšou súčasťou procesu indexovania a vyhľadávania. Je to analyzátor, ktorý konvertuje čistý text do tokenov a výrazov, aby ich bolo možné prehľadať. To nie je jediná zodpovednosť analyzátora. Analyzátor používa na výrobu tokenov tokenizér. Analyzátor tiež vykonáva nasledujúce úlohy:
- Kmeň: Analyzátor prevádza slovo na kmeň. To znamená, že výraz „kvety“ sa mení na kmeňové slovo „kvetina“. Po spustení vyhľadávania výrazu „kvetina“ sa dokument vráti.
- Filtrovanie: Analyzátor tiež filtruje zastavovacie slová ako „,“ je, atď. pretože tieto slová priťahujú akékoľvek dotazy, ktoré majú byť spustené, a nie sú produktívne.
- Normalizácia: Tento proces odstráni akcenty a iné označenia znakov.
Toto je normálna zodpovednosť spoločnosti StandardAnalyzer.
Príklad aplikácie
Na vytvorenie vzorového projektu pre náš príklad použijeme jeden z mnohých archívov Maven. Ak chcete vytvoriť projekt, vykonajte nasledujúci príkaz v adresári, ktorý použijete ako pracovný priestor:
archív typu mvn: generate -DgroupId = com.linuxhint.príklad -DartifactId = LH-LuceneExample -DarchetypeArtifactId = maven-archetype-quickstart -DinteractiveMode = falseAk používate maven prvýkrát, vykonanie príkazu generate bude trvať niekoľko sekúnd, pretože maven musí stiahnuť všetky požadované pluginy a artefakty, aby mohol vykonať generačnú úlohu. Takto vyzerá výstup projektu:
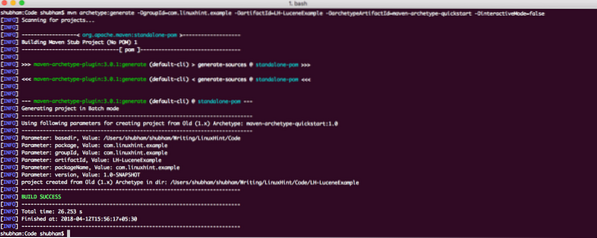
Nastavenie projektu
Po vytvorení projektu ho môžete otvoriť vo svojom obľúbenom IDE. Ďalším krokom je pridanie vhodných závislostí Maven do projektu. Tu je pom.xml súbor s príslušnými závislosťami:
Nakoniec, aby sme pochopili všetky JAR, ktoré sa pridajú do projektu, keď sme pridali túto závislosť, môžeme spustiť jednoduchý príkaz Maven, ktorý nám umožní vidieť kompletný strom závislostí projektu, keď k nemu pridáme nejaké závislosti. Tu je príkaz, ktorý môžeme použiť:
závislosť mvn: stromKeď spustíme tento príkaz, zobrazí sa nám tento strom závislostí: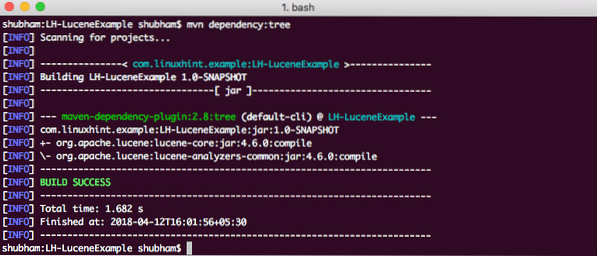
Nakoniec vytvoríme triedu SimpleIndexer, ktorá sa spustí
import java.io.Spis;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analýza.Analyzátor;
import org.apache.lucene.analýza.štandard.StandardAnalyzer;
import org.apache.lucene.dokument.Dokument;
import org.apache.lucene.dokument.StoredField;
import org.apache.lucene.dokument.Textové pole;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.obchod.FSDirectory;
import org.apache.lucene.util.Verzia;
verejná trieda SimpleIndexer
private static final String indexDirectory = "/ Users / shubham / niekam / LH-LuceneExample / Index";
private static final String dirToBeIndexed = "/ Users / shubham / niekam / LH-LuceneExample / src / main / java / com / linuxhint / príklad";
public static void main (String [] args) vyvolá výnimku
File indexDir = nový súbor (indexDirectory);
Súbor dataDir = nový súbor (dirToBeIndexed);
SimpleIndexer indexer = nový SimpleIndexer ();
int numIndexed = indexátor.index (indexDir, dataDir);
Systém.von.println ("Celkovo indexovanych suborov" + numIndexed);
private int index (File indexDir, File dataDir) vrhá IOException
Analyzátor analyzátor = nový StandardAnalyzer (verzia.LUCENE_46);
Konfigurácia IndexWriterConfig = nová IndexWriterConfig (verzia.LUCENE_46,
analyzátor);
IndexWriter indexWriter = nový IndexWriter (FSDirectory.otvorené (indexDir),
konfigurácia);
File [] files = dataDir.listFiles ();
pre (Súbor f: súbory)
Systém.von.println ("Indexačný súbor" + f.getCanonicalPath ());
Dokument doc = nový dokument ();
doc.add (nový TextField ("obsah", nový FileReader (f)));
doc.add (nový StoredField ("názov súboru"), f.getCanonicalPath ()));
indexWriter.addDocument (doc);
int numIndexed = indexWriter.maxDoc ();
indexWriter.Zavrieť();
návrat numIndexed;
V tomto kóde sme práve vytvorili inštanciu dokumentu a pridali nové pole, ktoré predstavuje obsah súboru. Tu je výstup, ktorý dostaneme, keď spustíme tento súbor:
Indexovací súbor / Používatelia / shubham / niekde / LH-LuceneExample / src / main / java / com / linuxhint / príklad / SimpleIndexer.javaCelkový počet indexovaných súborov 1
V rámci projektu sa tiež vytvorí nový adresár s nasledujúcim obsahom:
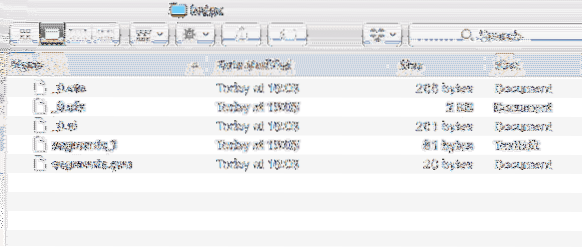
Údaje indexu
Budeme analyzovať, čo sú všetky súbory vytvorené v tomto indexe, v ďalších lekciách pre Lucene.
Záver
V tejto lekcii sme sa pozreli na to, ako Apache Lucene funguje, a vytvorili sme tiež jednoduchý príklad aplikácie, ktorá bola založená na Maven a java.


