Toto je článok nadväzujúci na predchádzajúce dva [2,3]. Doteraz sme načítali indexované dáta do úložiska Apache Solr a na ne sme sa pýtali. Teraz sa dozviete, ako pripojiť systém správy relačných databáz PostgreSQL [4] k Apache Solr a ako v ňom hľadať pomocou schopností Solr. Je preto potrebné vykonať niekoľko krokov, ktoré sú podrobnejšie popísané nižšie - nastavenie PostgreSQL, príprava dátovej štruktúry v databáze PostgreSQL, pripojenie PostgreSQL k Apache Solr a vyhľadávanie.
Krok 1: Nastavenie PostgreSQL
O aplikácii PostgreSQL - krátka informácia
PostgreSQL je dômyselný objektovo-relačný systém správy databázy. Je k dispozícii na použitie a aktívnym vývojom prešlo už viac ako 30 rokov. Pochádza z Kalifornskej univerzity, kde sa považuje za nástupcu spoločnosti Ingres [7].
Od začiatku je k dispozícii v rámci open-source (GPL), ktorý sa dá bezplatne používať, upravovať a distribuovať. To je široko používaný a veľmi populárny v priemysle. PostgreSQL bol pôvodne navrhnutý na spustenie iba v systémoch UNIX / Linux a neskôr bol navrhnutý na spustenie v iných systémoch, ako sú Microsoft Windows, Solaris a BSD. Aktuálny vývoj PostgreSQL uskutočňujú na celom svete početní dobrovoľníci.
Nastavenie PostgreSQL
Pokiaľ to ešte nie je urobené, nainštalujte PostgreSQL server a klienta lokálne, napríklad na Debian GNU / Linux, ako je popísané nižšie, pomocou apt. Dva články sa zaoberajú PostgreSQL - článok Yunisa Saida [5] pojednáva o nastavení na Ubuntu. Stále však iba škriabe povrch, zatiaľ čo môj predchádzajúci článok sa zameriava na kombináciu PostgreSQL s GIS nadstavbou PostGIS [6]. V tomto popise sú zhrnuté všetky kroky, ktoré potrebujeme pre toto konkrétne nastavenie.
# apt nainštalovať postgresql-13 postgresql-client-13Ďalej pomocou príkazu pg_isready overte, či je server PostgreSQL spustený. Toto je obslužný program, ktorý je súčasťou balíka PostgreSQL.
# pg_isready/ var / run / postgresql: 5432 - pripojenia sú akceptované
Vyššie uvedený výstup ukazuje, že PostgreSQL je pripravený a čaká na prichádzajúce pripojenia na porte 5432. Pokiaľ nie je stanovené inak, jedná sa o štandardnú konfiguráciu. Ďalším krokom je nastavenie hesla pre používateľa systému UNIX Postgres:
# passwd PostgresPamätajte, že PostgreSQL má svoju vlastnú databázu používateľov, zatiaľ čo administratívny používateľ PostgreSQL Postgres ešte nemá heslo. Predchádzajúci krok je potrebné urobiť aj pre používateľa PostgreSQL Postgres:
# su - Postgres$ psql -c "ZMENIŤ UŽÍVATEĽA Postgres S HESLOM 'heslo';"
Pre jednoduchosť je zvolené heslo iba heslo a malo by byť nahradené bezpečnejšou frázou hesla v iných systémoch ako je testovanie. Vyššie uvedený príkaz zmení internú používateľskú tabuľku PostgreSQL. Dajte pozor na rôzne úvodzovky - heslo v jednoduchých úvodzovkách a dotaz SQL v úvodzovkách, ktoré zabránia interpretovi shellu v nesprávnom vyhodnotení príkazu. Pred dvojité úvodzovky na konci príkazu tiež pridajte za dotazom SQL bodkočiarku.
Ďalej sa z administratívnych dôvodov pripojte k PostgreSQL ako používateľ Postgres s predtým vytvoreným heslom. Príkaz sa volá psql:
$ psqlPripojenie z Apache Solr k databáze PostgreSQL sa vykonáva ako užívateľské riešenie. Poďme teda pridať riešenie používateľa PostgreSQL a nastaviť mu zodpovedajúce riešenie hesla naraz:
$ VYTVORTE UŽÍVATEĽA solr S HESLOM 'solr';Pre jednoduchosť je zvolené heslo iba solr a malo by byť nahradené bezpečnejšou frázou hesla v systémoch, ktoré sú vo výrobe.
Krok 2: Príprava dátovej štruktúry
Na ukladanie a načítanie údajov je potrebná zodpovedajúca databáza. Nasledujúci príkaz vytvorí databázu automobilov, ktorá patrí používateľovi solr a bude použitá neskôr.
$ VYTVORTE DATABÁZU automobily S VLASTNÍKOM = solr;Potom sa pripojte k novovytvoreným databázovým automobilom ako používateľ solr. Voľba -d (krátka voľba pre -dbname) definuje názov databázy a -U (krátka voľba pre -username) meno používateľa PostgreSQL.
$ psql -d autá -U solrPrázdna databáza nie je užitočná, ale štruktúrované tabuľky s obsahom áno. Vytvorte štruktúru stolových automobilov nasledovne:
$ CREATE TABLE autá (id int,
vyrobiť varchar (100),
model varchar (100),
popis varchar (100),
farebný varchar (50),
cena int
);
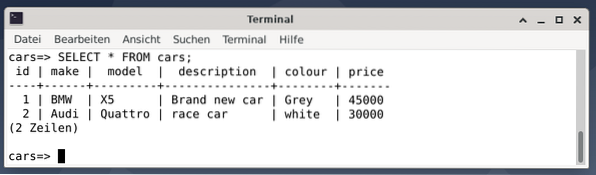
Stolové autá obsahujú šesť dátových polí - id (celé číslo), make (reťazec s dĺžkou 100), model (reťazec s dĺžkou 100), popis (reťazec s dĺžkou 100), farba (reťazec s dĺžkou 50) a cena (celé číslo). Ak chcete mať nejaké ukážkové údaje, pridajte do tabuliek nasledujúce hodnoty ako príkazy SQL:
$ INSERT INTO cars (identifikačné číslo, značka, model, popis, farba, cena)HODNOTY (1, „BMW“, „X5“, „chladné auto“, „sivé“, 45000);
$ INSERT INTO cars (identifikačné číslo, značka, model, popis, farba, cena)
HODNOTY (2, „Audi“, „Quattro“, „závodné auto“, „biele“, 30000);
Výsledkom sú dva príspevky predstavujúce sivé BMW X5, ktoré stojí 45 000 USD, označované ako chladné auto, a biele pretekárske auto Audi Quattro, ktoré stojí 30000 USD.
Ďalej ukončite konzolu PostgreSQL pomocou \ q alebo ukončite.
$ \ qKrok 3: Pripojenie PostgreSQL k Apache Solr
Spojenie PostgreSQL a Apache Solr je založené na dvoch softvéroch - ovládač Java pre PostgreSQL s názvom ovládač JDBC (Java Database Connectivity) a rozšírenie konfigurácie servera Solr. Ovládač JDBC pridáva do PostgreSQL rozhranie Java a ďalšia položka v konfigurácii Solr hovorí spoločnosti Solr, ako sa pripojiť k PostgreSQL pomocou ovládača JDBC.
Pridanie ovládača JDBC sa vykoná ako užívateľ root nasledujúcim spôsobom a nainštaluje sa ovládač JDBC z úložiska balíkov Debian:
# apt-get install libpostgresql-jdbc-javaNa strane Apache Solr musí tiež existovať zodpovedajúci uzol. Ak to ešte nie je urobené, ako používateľ systému UNIX, vytvorte automobily uzlov nasledovne:
$ bin / solr create -c carsĎalej rozšírte konfiguráciu Solr pre novovytvorený uzol. Pridajte nasledujúce riadky do súboru / var / solr / data / cars / conf / solrconfig.xml:
db-data-config.xmlĎalej vytvorte súbor / var / solr / data / cars / conf / data-config.xml a uložte doň nasledujúci obsah:
Riadky vyššie zodpovedajú predchádzajúcemu nastaveniu a definujú ovládač JDBC, určia port 5432 na pripojenie k PostgreSQL DBMS ako používateľovi so zodpovedajúcim heslom a nastavia, aby sa dotaz SQL vykonával z PostgreSQL. Pre jednoduchosť je to príkaz SELECT, ktorý zachytáva celý obsah tabuľky.
Potom reštartujte server Solr, aby sa zmeny vykonali. Ako užívateľ root vykonajte nasledujúci príkaz:
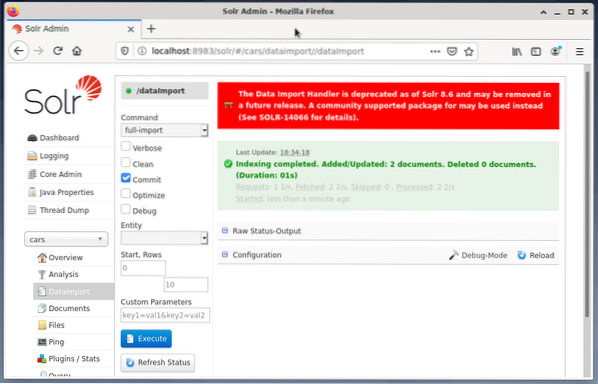
# systemctl restart solrPosledným krokom je import údajov, napríklad pomocou webového rozhrania Solr. V poli pre výber uzlov sa vyberú vozne uzlov, potom z ponuky Uzol pod položkou Dataimport nasleduje výber úplného importu z ponuky Príkaz priamo na ňu. Nakoniec stlačte tlačidlo Execute. Obrázok nižšie ukazuje, že spoločnosť Solr úspešne indexovala údaje.
Krok 4: Dopytovanie údajov z DBMS
Predchádzajúci článok [3] sa zaoberá podrobným dopytovaním údajov, načítaním výsledku a výberom požadovaného výstupného formátu - CSV, XML alebo JSON. Dotazovanie údajov sa vykonáva podobne, ako ste sa už dozvedeli predtým, a používateľ tak nevidí žiadny rozdiel. Solr robí všetku prácu v zákulisí a komunikuje s PostgreSQL DBMS pripojeným tak, ako je definované vo vybranom jadre alebo klastri Solr.
Používanie Solr sa nemení a dotazy je možné zadávať cez administrátorské rozhranie Solr alebo pomocou curl alebo wget na príkazovom riadku. Na server Solr odošlete žiadosť o získanie s konkrétnou adresou URL (dotaz, aktualizácia alebo odstránenie). Solr spracuje požiadavku pomocou DBMS ako pamäťovej jednotky a vráti výsledok žiadosti. Ďalej post-spracovajte odpoveď lokálne.
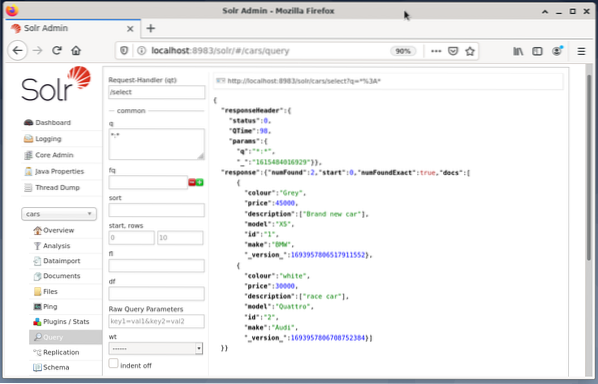
Nasledujúci príklad zobrazuje výstup dotazu „/ select?q = *. * ”Vo formáte JSON v administrátorskom rozhraní Solr. Dáta sa získavajú z databázových automobilov, ktoré sme vytvorili skôr.
Záver
Tento článok ukazuje, ako dopytovať databázu PostgreSQL z Apache Solr, a vysvetľuje príslušné nastavenie. V ďalšej časti tejto série sa naučíte, ako kombinovať niekoľko uzlov Solr do klastra Solr.
O autoroch
Jacqui Kabeta je environmentalistka, zanietená výskumníčka, trénerka a mentorka. Vo viacerých afrických krajinách pracovala v IT priemysle a v prostredí mimovládnych organizácií.
Frank Hofmann je IT vývojár, tréner a autor a najradšej pracuje z Berlína, Ženevy a Kapského Mesta. Spoluautor knihy Debian Package Management Book, ktorá je k dispozícii na stránke dpmb.org
Odkazy a referencie
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. 1. časť, https: // linuxhint.com / apache-solr-setup-a-node /
- [3] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. Dopytovanie údajov. 2. časť, http: // linuxhint.com
- [4] PostgreSQL, https: // www.postgresql.org /
- [5] Younis Said: Ako nainštalovať a nastaviť databázu PostgreSQL na Ubuntu 20.04, https: // linuxhint.com / install_postgresql_-ubuntu /
- [6] Frank Hofmann: Nastavenie PostgreSQL s PostGIS na Debiane GNU / Linux 10, https: // linuxhint.com / setup_postgis_debian_postgres /
- [7] Ingres, Wikipedia, https: // en.wikipedia.org / wiki / Ingres_ (databáza)


