Toto je článok nadväzujúci na predchádzajúci. Pokryjeme, ako spresniť dopyt, formulovať zložitejšie kritériá vyhľadávania s rôznymi parametrami a porozumieť rôznym webovým formulárom stránky dotazu Apache Solr. Budeme tiež diskutovať o tom, ako postprocesovať výsledok vyhľadávania pomocou rôznych výstupných formátov, ako sú XML, CSV a JSON.
Dopytovanie Apache Solr
Apache Solr je navrhnutý ako webová aplikácia a služba, ktorá beží na pozadí. Výsledkom je, že akákoľvek klientská aplikácia môže komunikovať so spoločnosťou Solr odosielaním otázok do nej (zameranie tohto článku), manipuláciou s jadrom dokumentu pridávaním, aktualizáciou a mazaním indexovaných údajov a optimalizáciou základných údajov. Existujú dve možnosti - prostredníctvom palubnej dosky / webového rozhrania alebo pomocou API zaslaním príslušnej žiadosti.
Je bežné používať prvá možnosť na testovacie účely a nie na pravidelný prístup. Obrázok nižšie zobrazuje informačný panel z používateľského rozhrania správy Apache Solr s rôznymi formulármi dotazov vo webovom prehliadači Firefox.
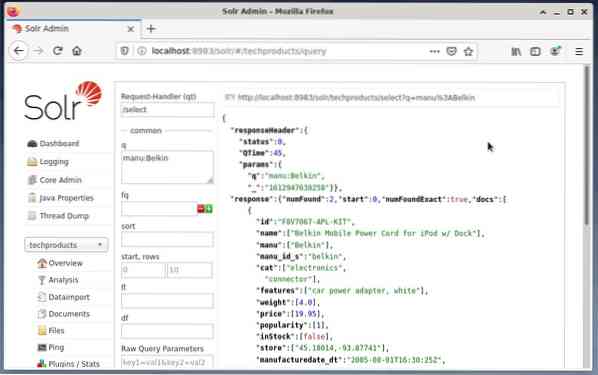
Najskôr z ponuky pod poľom na výber jadra vyberte položku ponuky „Dotaz“. Na nasledujúcom paneli sa zobrazí niekoľko vstupných polí nasledovne:
- Vybavovač požiadaviek (qt):
Definujte, aký druh žiadosti chcete poslať spoločnosti Solr. Môžete si vybrať medzi predvolenými obslužnými nástrojmi požiadaviek „/ select“ (dopyt indexovaných údajov), „/ update“ (aktualizácia indexovaných údajov) a „/ delete“ (odstránenie zadaných indexovaných údajov) alebo samostatne definované. - Udalosť dopytu (q):
Definujte, ktoré názvy polí a hodnoty sa majú vybrať. - Filtrovať dotazy (často kladené otázky):
Obmedzte nadmnožinu dokumentov, ktoré je možné vrátiť bez ovplyvnenia skóre dokumentu. - Poradie zoradenia (zoradenie):
Definujte poradie triedenia výsledkov dotazu vzostupne alebo zostupne - Výstupné okno (začiatok a riadky):
Obmedzte výstup na určené prvky - Zoznam polí (fl):
Obmedzuje informácie obsiahnuté v odpovedi na dotaz na zadaný zoznam polí. - Výstupný formát (hmot.):
Definujte požadovaný výstupný formát. Predvolená hodnota je JSON.
Kliknutím na tlačidlo Vykonať dopyt sa spustí požadovaná požiadavka. Praktické príklady nájdete nižšie.
Ako druhá možnosť, môžete poslať požiadavku pomocou API. Toto je požiadavka HTTP, ktorú môže na server Apache Solr odoslať ľubovoľná aplikácia. Solr spracuje požiadavku a vráti odpoveď. Špeciálnym prípadom je pripojenie k Apache Solr cez Java API. Tento bol zadaný outsourcingu do samostatného projektu s názvom SolrJ [7] - Java API bez nutnosti pripojenia HTTP.
Syntax dopytu
Syntax dotazu je najlepšie opísaná v [3] a [5]. Rôzne názvy parametrov priamo zodpovedajú názvom vstupných polí vo formulároch vysvetlených vyššie. V nasledujúcej tabuľke je uvedený zoznam plus praktické príklady.
Register parametrov dopytu
| Parameter | Popis | Príklad |
|---|---|---|
| q | Hlavný parameter dotazu Apache Solr - názvy a hodnoty polí. Ich skóre podobnosti dokumentuje výrazy v tomto parametri. | Id: 5 autá: * adilla * *: X5 |
| časté otázky | Výslednú množinu obmedzte na nadmnožinu dokumentov, ktoré zodpovedajú filtru, napríklad definovanému pomocou analyzátora dotazov na rozsah funkcií | Model id, model |
| začať | Ofsety pre výsledky na stránke (začiatok). Predvolená hodnota tohto parametra je 0. | 5 |
| riadkov | Korekcie výsledkov stránky (koniec). Hodnota tohto parametra je predvolene 10 | 15 |
| triediť | Určuje zoznam polí oddelených čiarkami, na základe ktorých sa majú zoradiť výsledky dotazu | model asc |
| fl | Určuje zoznam polí, ktoré sa majú vrátiť pre všetky dokumenty v množine výsledkov | Model id, model |
| hm | Tento parameter predstavuje typ zapisovača odpovedí, ktorý sme chceli zobraziť. Hodnota tohto súboru je predvolene JSON. | json xml |
Vyhľadávania sa vykonávajú prostredníctvom požiadavky HTTP GET s reťazcom dopytu v parametri q. Nasledujúce príklady objasnia, ako to funguje. Používa sa curl na odoslanie dotazu do systému Solr, ktorý je nainštalovaný lokálne.
- Načítajte všetky súbory údajov z kučier jadra automobilov http: // localhost: 8983 / solr / cars / dotaz?q = *: *
- Načítajte všetky súbory údajov z hlavných automobilov, ktoré majú ID 5 zvlnenie http: // localhost: 8983 / solr / cars / dotaz?q = id: 5
- Získajte poľný model zo všetkých súborov údajov základných automobilov
Možnosť 1 (s únikom a): zvlnenie http: // localhost: 8983 / solr / cars / dopyt?q = id: * \ & fl = modelMožnosť 2 (dopyt jedným zaškrtnutím):
curl 'http: // localhost: 8983 / solr / cars / dopyt?q = id: * & fl = model ' - Načítajte všetky množiny údajov základných automobilov zoradených podľa ceny v zostupnom poradí a vygenerujte iba polia, ktoré tvoria, model a cena (verzia s jednoduchým začiarknutím): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
zoradiť = cena zostupne &
fl = značka, model, cena ' - Načítajte prvých päť súborov údajov základných automobilov zoradených podľa ceny v zostupnom poradí a výstup iba zo značiek, modelov a cien (verzia s jednoduchým začiarknutím): curl http: // localhost: 8983 / solr / cars / dotaz - d '
q = *: * &
riadky = 5 &
zoradiť = cenový popis &
fl = značka, model, cena ' - Načítajte prvých päť súborov údajov základných automobilov zoradených podľa ceny v zostupnom poradí a výstup iba zo značiek, modelov a cien plus ich skóre relevancie (verzia s jednoduchým začiarknutím): curl http: // localhost: 8983 / solr / autá / dopyt -d '
q = *: * &
riadky = 5 &
zoradiť = cenový popis &
fl = značka, model, cena, skóre ' - Vrátiť všetky uložené polia aj skóre relevancie: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, skóre '
Ďalej môžete definovať svoj vlastný obslužný program požiadaviek, ktorý bude posielať voliteľné parametre požiadavky analyzátoru dotazov, aby bolo možné riadiť, ktoré informácie sa vrátia.
Analyzátory dotazov
Apache Solr používa takzvaný analyzátor dotazov - komponent, ktorý prevádza váš vyhľadávací reťazec na konkrétne pokyny pre vyhľadávací stroj. Analyzátor dotazov stojí medzi vami a dokumentom, ktorý hľadáte.
Solr prichádza s rôznymi typmi syntaktických analyzátorov, ktoré sa líšia v spôsobe spracovania zadaného dotazu. Analyzátor štandardných dotazov funguje dobre pre štruktúrované dotazy, je však menej tolerantný voči syntaktickým chybám. Zároveň sú DisMax aj Extended DisMax Query Parser optimalizované pre dotazy podobné prirodzenému jazyku. Sú určené na spracovanie jednoduchých fráz zadaných používateľmi a na hľadanie jednotlivých výrazov vo viacerých poliach s použitím rôznej váhy.
Okrem toho spoločnosť Solr ponúka aj takzvané funkčné dotazy, ktoré umožňujú kombináciu funkcií s dotazom s cieľom vygenerovať konkrétne skóre relevancie. Tieto analyzátory sa nazývajú analyzátor dotazov na funkcie a analyzátor dotazov na rozsah funkcií. Nasledujúci príklad ukazuje, že druhý z nich vyberie všetky súbory údajov pre „bmw“ (uložené v značke dátového poľa) s modelmi od 318 do 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = značka: bmw &
fq = model: [318 TO 323] '
Dodatočné spracovanie výsledkov
Posielanie dotazov na Apache Solr je jednou časťou, ale následné spracovanie výsledku vyhľadávania z druhej. Najskôr si môžete vybrať medzi rôznymi formátmi odpovedí - od JSON po XML, CSV a zjednodušeným formátom Ruby. Jednoducho zadajte zodpovedajúci parameter wt v dotaze. Nižšie uvedený príklad kódu to demonštruje na získanie množiny údajov vo formáte CSV pre všetky položky pomocou príkazu curl s únikom &:
zvlnenie http: // localhost: 8983 / solr / cars / dopyt?q = id: 5 \ & wt = csvVýstupom je zoznam oddelený čiarkami:

Ak chcete získať výsledok ako údaje XML, ale iba dve výstupné polia tvoria a modelujú, spustite nasledujúci dotaz:
curl http: // localhost: 8983 / solr / cars / dopyt?q = *: * \ & fl = značka, model \ & wt = xmlVýstup je iný a obsahuje hlavičku odpovede aj skutočnú odpoveď:
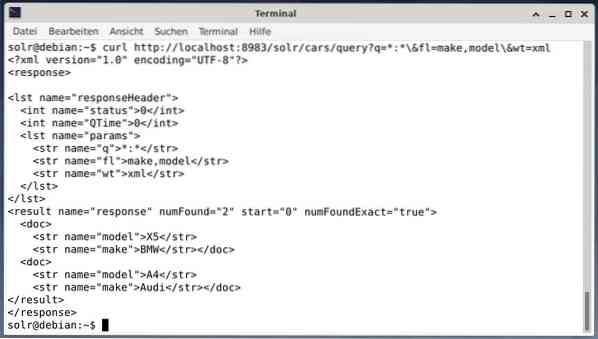
Wget jednoducho vytlačí prijaté dáta na štandardný výstup. To vám umožňuje postprocesovať odpoveď pomocou štandardných nástrojov príkazového riadku. Uvádzame niekoľko jq [9] pre JSON, xsltproc, xidel, xmlstarlet [10] pre XML a csvkit [11] pre formát CSV.
Záver
Tento článok ukazuje rôzne spôsoby odosielania dotazov do Apache Solr a vysvetľuje, ako spracovať výsledok vyhľadávania. V ďalšej časti sa naučíte, ako používať Apache Solr na vyhľadávanie v PostgreSQL, systéme správy relačnej databázy.
O autoroch
Jacqui Kabeta je environmentalistka, zanietená výskumníčka, trénerka a mentorka. Vo viacerých afrických krajinách pracovala v IT priemysle a v prostredí mimovládnych organizácií.
Frank Hofmann je IT vývojár, tréner a autor a najradšej pracuje z Berlína, Ženevy a Kapského Mesta. Spoluautor knihy Debian Package Management Book, ktorá je k dispozícii na stránke dpmb.org
Odkazy a referencie
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. 1. časť, http: // linuxhint.com
- [3] Yonik Seelay: Synr Query Syntax, http: // yonik.com / solr / query-syntax /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Dotazovanie na dáta, Tutorialspoint, https: // www.výučbový bod.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucene.apache.org /
- [7] SolrJ, https: // lucene.apache.org / solr / sprievodca / 8_8 / using-solrj.html
- [8] zvlnenie, https: // zvlnenie.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.sieť /
- [11] csvkit, https: // csvkit.readthedocs.io / sk / najnovšie /


