Inštalácia Tesseract OCR v Linuxe
Tesseract OCR je predvolene k dispozícii na väčšine distribúcií Linuxu. Môžete ho nainštalovať do Ubuntu pomocou nasledujúceho príkazu:
$ sudo apt nainštalovať tesseract-ocrPodrobné pokyny pre ďalšie distribúcie sú k dispozícii tu. Aj keď je Tesseract OCR štandardne k dispozícii v úložiskách mnohých distribúcií Linuxu, pre lepšiu presnosť a analýzu sa odporúča nainštalovať najnovšiu verziu z vyššie uvedeného odkazu.
Inštalácia podpory ďalších jazykov v Tesseract OCR
Tesseract OCR obsahuje podporu pre detekciu textu vo viac ako 100 jazykoch. Podporu na detekciu textu v anglickom jazyku však získate iba s predvolenou inštaláciou v Ubuntu. Ak chcete pridať podporu pre analýzu ďalších jazykov v Ubuntu, spustite príkaz v nasledujúcom formáte:
$ sudo apt nainštalovať tesseract-ocr-hinVyššie uvedený príkaz pridá podporu pre hindský jazyk do Tesseract OCR. Inštaláciou podpory jazykových skriptov môžete niekedy dosiahnuť lepšiu presnosť a výsledky. Napríklad inštalácia a používanie balíka tesseract pre skript Devanagari „tesseract-ocr-script-deva“ mi prinieslo oveľa presnejšie výsledky ako použitie balíka „tesseract-ocr-hin“.
V Ubuntu nájdete správne názvy balíkov pre všetky jazyky a skripty spustením nasledujúceho príkazu:
tesseract hľadania $ apt-cache-Po identifikácii správneho názvu balíka, ktorý chcete nainštalovať, nahraďte ním reťazec „tesseract-ocr-hin“ v prvom vyššie uvedenom príkaze.
Používanie OCR Tesseract na extrakciu textu z obrázkov
Zoberme si príklad obrázka zobrazeného nižšie (prevzatý zo stránky Wikipedia pre Linux):

Ak chcete extrahovať text z vyššie uvedeného obrázka, musíte spustiť príkaz v nasledujúcom formáte:
$ zachytenie tesseractu.výstup png -l anglSpustením vyššie uvedeného príkazu získate nasledujúci výstup:
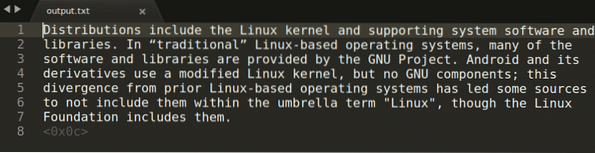
Vo vyššie uvedenom príkaze „capture.png “označuje obrázok, z ktorého chcete extrahovať text. Zachytený výstup sa potom uloží do „výstupu“.súbor txt “. Jazyk môžete zmeniť nahradením argumentu „eng“ vlastným výberom. Ak chcete zobraziť všetky platné jazyky, spustite nasledujúci príkaz:
$ tesseract --list-langsZobrazí sa skratkové kódy pre všetky jazyky podporované Tesseract OCR vo vašom systéme. V predvolenom nastavení sa ako výstup zobrazí iba „eng“. Ak však inštalujete balíčky pre ďalšie jazyky, ako je vysvetlené vyššie, tento príkaz zobrazí zoznam ďalších jazykov, ktoré môžete použiť na detekciu textu (ako trojpísmenové jazykové kódy ISO 639).
Ak obrázok obsahuje text vo viacerých jazykoch, najskôr definujte primárny jazyk a potom ďalšie jazyky oddelené znamienkami plus.
$ zachytenie tesseractu.výstup png -l eng + fraAk chcete výstup uložiť ako prehľadávateľný súbor PDF, spustite príkaz v nasledujúcom formáte:
$ zachytenie tesseractu.výstup png -l eng pdfUpozorňujeme, že prehľadávateľný súbor PDF nebude obsahovať žiadny upraviteľný text. Zahŕňa pôvodný obrázok a ďalšiu vrstvu obsahujúcu rozpoznaný text vložený do obrázka. Takže aj keď budete môcť pomocou ľubovoľnej čítačky PDF presne vyhľadávať text v súbore PDF, nebudete môcť text upravovať.
Ďalším bodom, ktorý by ste si mali uvedomiť, je, že presnosť detekcie textu sa výrazne zvyšuje, ak je obrazový súbor vysokej kvality. Ak máte na výber, vždy používajte bezstratové formáty súborov alebo súbory PNG. Používanie súborov JPG nemusí priniesť najlepšie výsledky.
Extrahovanie textu z viacstranového súboru PDF
Tesseract OCR natívne nepodporuje extrakciu textu zo súborov PDF. Je však možné extrahovať text z viacstranového súboru PDF prevedením každej stránky do obrazového súboru. Spustením nasledujúceho príkazu preveďte súbor PDF na sadu obrázkov:
súbor $ pdftoppm -png.výstup pdfZa každú stránku súboru PDF získate zodpovedajúci „výstup-1.png “,„ výstup-2.png “atď.
Ak chcete teraz z týchto obrázkov extrahovať text pomocou jedného príkazu, budete musieť v príkaze bash použiť príkaz „for loop“:
$ za vstup i *.png; urobiť tesseract "$ i" "výstup- $ i" -l eng; hotový;Spustením vyššie uvedeného príkazu sa extrahuje text zo všetkých „.png ”súbory nájdené v pracovnom adresári a uložte rozpoznaný text do„ output-original_filename.txt ”súbory. Strednú časť príkazu môžete upraviť podľa svojich potrieb.
Ak chcete skombinovať všetky textové súbory obsahujúce rozpoznaný text, spustite nasledujúci príkaz:
$ mačka *.txt> pripojil sa.TXTProces extrakcie textu z viacstranového súboru PDF do prehľadávateľných súborov PDF je takmer rovnaký. K príkazu musíte dodať ďalší argument „pdf“:
$ za vstup i *.png; urobiť tesseract "$ i" "výstup- $ i" -l eng pdf; hotový;Ak chcete skombinovať všetky prehľadávateľné súbory PDF obsahujúce rozpoznaný text, spustite nasledujúci príkaz:
$ pdfunite *.pdf pripojil.pdfProgram „pdftoppm“ aj „pdfunite“ sú predvolene nainštalované v najnovšej stabilnej verzii Ubuntu.
Výhody a nevýhody extrakcie textu v TXT a prehľadávateľných súboroch PDF
Ak extrahujete rozpoznaný text do súborov TXT, získate upraviteľný textový výstup. Stratí sa však akékoľvek formátovanie dokumentu (tučné, kurzíva atď.). Prehľadávateľné súbory PDF zachovajú pôvodné formátovanie, stratíte však možnosti úprav textu (stále môžete kopírovať nespracovaný text). Ak otvoríte prehľadávateľný súbor PDF v ľubovoľnom editore PDF, zobrazia sa v ňom vložené obrázky, nie hrubý textový výstup. Konvertovaním prehľadávateľných súborov PDF do formátu HTML alebo EPUB získate tiež vložené obrázky.
Záver
Tesseract OCR je dnes jedným z najbežnejšie používaných OCR motorov. Je to bezplatný open-source a podporuje viac ako sto jazykov. Ak používate OCR Tesseract, nezabudnite použiť obrázky vo vysokom rozlíšení a opraviť jazykové kódy v argumentoch príkazového riadku, aby ste zlepšili presnosť detekcie textu.


