Apache Spark je nástroj na analýzu údajov, ktorý možno použiť na spracovanie údajov z HDFS, S3 alebo iných zdrojov údajov v pamäti. V tomto príspevku nainštalujeme Apache Spark na Ubuntu 17.10 stroj.
Verzia Ubuntu
V tejto príručke budeme používať Ubuntu verzie 17.10 (GNU / Linux 4.13.0-38-generický x86_64).
Apache Spark je súčasťou ekosystému Hadoop pre veľké dáta. Skúste nainštalovať Apache Hadoop a vytvorte s ním ukážkovú aplikáciu.
Aktualizácia existujúcich balíkov
Na spustenie inštalácie pre Spark je potrebné, aby sme náš stroj aktualizovali o najnovšie dostupné softvérové balíčky. Môžeme to urobiť pomocou:
sudo apt-get update && sudo apt-get -y dist-upgradePretože Spark je založený na Jave, musíme si ho nainštalovať na náš stroj. Môžeme použiť ktorúkoľvek verziu Java nad Java 6. Tu budeme používať Java 8:
sudo apt-get -y nainštalovať openjdk-8-jdk-headlessSťahujú sa súbory Spark
Na našom stroji teraz existujú všetky potrebné balíčky. Sme pripravení stiahnuť požadované súbory Spark TAR, aby sme ich mohli začať nastavovať a spustiť ukážkový program aj so Sparkom.
V tejto príručke budeme inštalovať Spark v2.3.0 k dispozícii tu:
Stránka na stiahnutie Spark
Stiahnite si príslušné súbory pomocou tohto príkazu:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / iskra-2.3.0-bin-hadoop2.7.tgzV závislosti od rýchlosti siete to môže trvať až niekoľko minút, pretože veľkosť súboru je veľká:
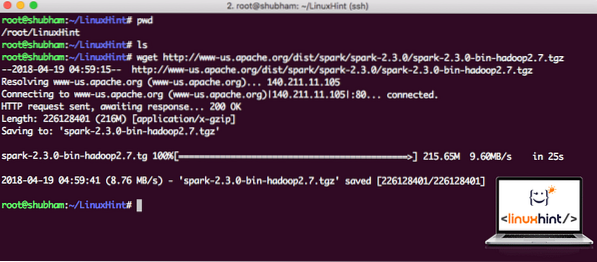
Sťahuje sa Apache Spark
Teraz, keď máme stiahnutý súbor TAR, môžeme rozbaliť aktuálny adresár:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgzBude to trvať niekoľko sekúnd, pretože archív má veľkú veľkosť:
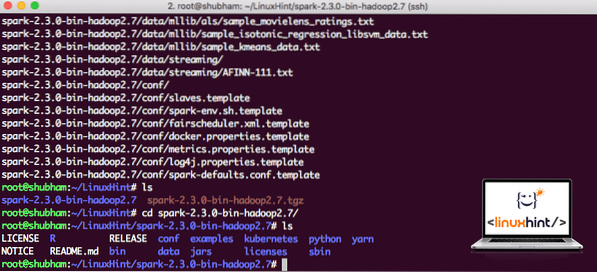
Archivované súbory v aplikácii Spark
Pokiaľ ide o budúcu aktualizáciu Apache Spark, môže to spôsobiť problémy v dôsledku aktualizácií cesty. Týmto problémom sa dá vyhnúť vytvorením mäkkého odkazu na Spark. Spustením tohto príkazu vytvoríte mäkký odkaz:
ln -s iskra-2.3.0-bin-hadoop2.7 iskraPridanie Spark na cestu
Aby sme mohli vykonávať Spark skripty, pridáme ich teraz na cestu. Ak to chcete urobiť, otvorte súbor bashrc:
vi ~ /.bashrcPridajte tieto riadky na koniec súboru .súbor bashrc, aby táto cesta mohla obsahovať cestu k spustiteľnému súboru Spark:
SPARK_HOME = / LinuxHint / sparkexport PATH = $ SPARK_HOME / bin: $ PATH
Teraz súbor vyzerá takto:
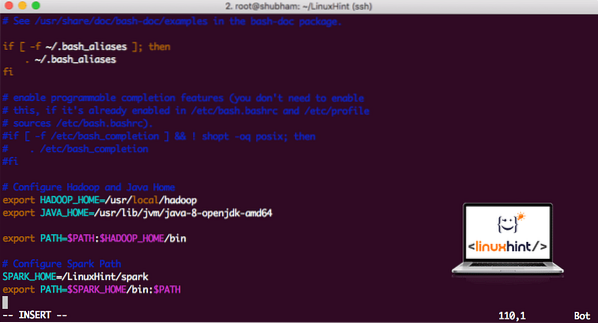
Pridanie Spark na PATH
Ak chcete aktivovať tieto zmeny, spustite nasledujúci príkaz pre súbor bashrc:
zdroj ~ /.bashrcSpúšťam Spark Shell
Teraz, keď sme priamo mimo adresára iskier, spustite nasledujúci príkaz na otvorenie shellu apark:
./ spark / bin / spark-shellUvidíme, že shell Spark je teraz otvorený:
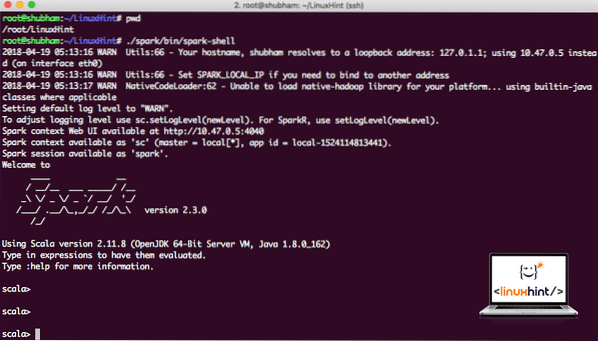
Spúšťam shell Spark
Na konzole vidíme, že Spark otvoril aj webovú konzolu na porte 404. Poďme to navštíviť:
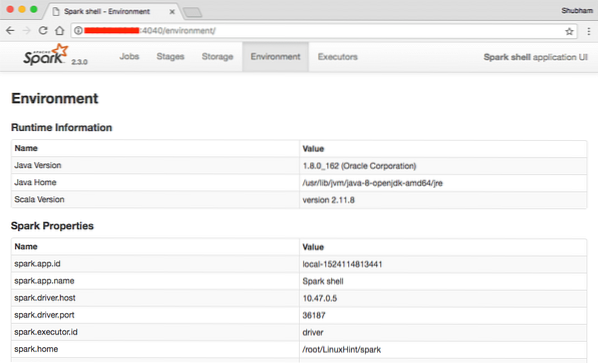
Webová konzola Apache Spark
Aj keď budeme pracovať na samotnej konzole, webové prostredie je dôležitým miestom, na ktoré sa treba pozerať, keď vykonávate ťažké úlohy Spark Job, aby ste vedeli, čo sa deje v každej úlohe Spark Job, ktorú vykonávate.
Skontrolujte verziu shellu Spark jednoduchým príkazom:
sc.verziaVrátime niečo ako:
res0: Reťazec = 2.3.0Vytvorenie ukážky aplikácie Spark v programe Scala
Teraz urobíme ukážkovú aplikáciu Word Counter s Apache Spark. Ak to chcete urobiť, najskôr načítajte textový súbor do kontextu Spark v prostredí Spark:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Údaje: org.apache.iskra.rdd.RDD [Reťazec] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] v súbore textFile o: 24
scala>
Teraz musí byť text v súbore rozdelený na tokeny, ktoré môže Spark spravovať:
scala> var tokens = Údaje.flatMap (s => s.split (""))tokeny: org.apache.iskra.rdd.RDD [String] = MapPartitionsRDD [2] na plochej mape o: 25
scala>
Teraz inicializujte počet pre každé slovo na 1:
scala> var tokens_1 = tokeny.mapa (s => (s, 1))tokens_1: org.apache.iskra.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] na mape o: 25
scala>
Nakoniec vypočítajte frekvenciu každého slova v súbore:
var sum_each = tokeny_1.reduceByKey ((a, b) => a + b)Je čas pozrieť sa na výstup programu. Zbierajte žetóny a ich príslušné počty:
scala> sum_each.zbierať ()res1: Array [(String, Int)] = Array ((balíček, 1), (pre, 3), (programy, 1), (spracovanie.,1), (Pretože, 1), (The, 1), (stránka) (http: // spark.apache.org / dokumentácia.html).,1), (zhluk.,1), (its, 1), ([run, 1), (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (niekoľko, 1), (Táto, 2), (graf, 1), (Úľ, 2), (úložisko, 1), ([„Špecifikácia, 1), (K, 2), („ priadza “) , 1), (Raz, 1), ([„Užitočné, 1), (radšej, 1), (SparkPi, 2), (engine, 1), (verzia, 1), (súbor, 1), (dokumentácia ,, 1), (spracovanie ,, 1), (the, 24), (are, 1), (systems.,1), (parametre, 1), (nie, 1), (odlišné, 1), (odkazovať, 2), (Interaktívne, 2), (R ,, 1), (dané.,1), (ak, 4), (zostavenie, 4), (keď, 1), (byť, 2), (testy, 1), (Apache, 1), (vlákno, 1), (programy ,, 1 ), (vrátane, 4), (./ bin / run-example, 2), (Spark.,1), (balík.,1), (1 000).count (), 1), (Verzie, 1), (HDFS, 1), (D ..
scala>
Vynikajúci! Boli sme schopní spustiť jednoduchý príklad počítadla slov pomocou programovacieho jazyka Scala s textovým súborom, ktorý už bol v systéme prítomný.
Záver
V tejto lekcii sme sa pozreli na to, ako môžeme nainštalovať a začať používať Apache Spark na Ubuntu 17.10 stroj a tiež na ňom spustite ukážkovú aplikáciu.
Prečítajte si viac príspevkov založených na Ubuntu tu.


