V tomto článku sa oboznámime so základným použitím skupiny podľa funkcií v pandónovom pytóne. Všetky príkazy sa vykonávajú v editore Pycharm.
Poďme diskutovať o hlavnom koncepte skupiny pomocou údajov zamestnanca. Vytvorili sme dátový rámec s niektorými užitočnými podrobnosťami o zamestnancovi (Employee_Names, Designation, Employee_city, Age).
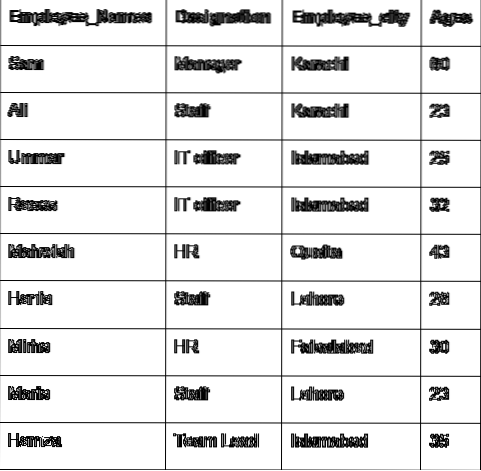
Zreťazenie reťazcov pomocou zoskupenia podľa funkcie
Pomocou funkcie groupby môžete spojiť reťazce. Rovnaké záznamy je možné spojiť s znakom „,“ v jednej bunke.
Príklad
V nasledujúcom príklade sme zoradili údaje na základe stĺpca Označenie zamestnancov a pripojili sa k zamestnancom, ktorí majú rovnaké označenie. Funkcia lambda sa aplikuje na „Zamestnanci_Name“.
importovať pandy ako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Označenie") ['Meno_zamestnanca'].apply (lambda Employee_Names: ','.pripojiť sa (mená zamestnancov)
tlač (df1)
Po vykonaní vyššie uvedeného kódu sa zobrazí nasledujúci výstup:
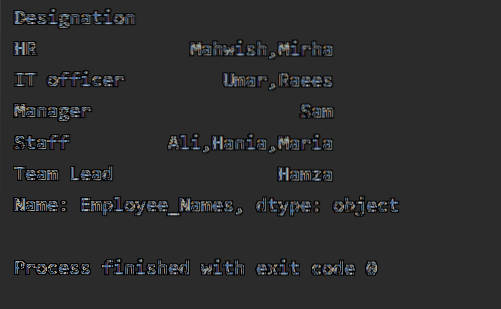
Zoraďovanie hodnôt vzostupne
Použite objekt groupby do bežného dátového rámca volaním '.to_frame () 'a potom na opätovné indexovanie použite reset_index (). Zoraďte hodnoty stĺpcov volaním sort_values ().
Príklad
V tomto príklade zoradíme vek zamestnanca vzostupne. Pomocou nasledujúcej časti kódu sme načítali „Employee_Age“ vo vzostupnom poradí s „Employee_Names“.
importovať pandy ako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].suma ().zarámovať().reset_index ().sort_values (by = 'Employee_Age')
tlač (df1)
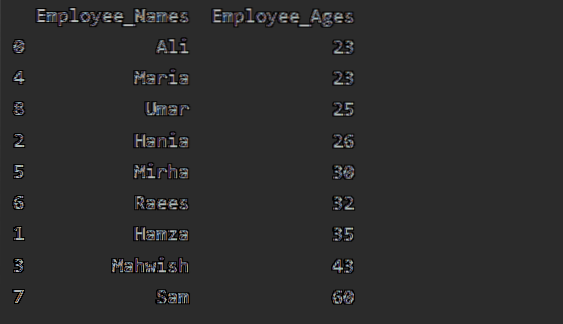
Použitie agregátov s groupby
Existuje niekoľko funkcií alebo agregácií, ktoré môžete použiť na skupiny údajov, ako napríklad count (), sum (), mean (), median (), mode (), std (), min (), max ().
Príklad
V tomto príklade sme použili funkciu 'count ()' s groupby na spočítanie zamestnancov, ktorí patria do rovnakého 'Employee_city'.
importovať pandy ako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').count ()
tlač (df1)
Ako vidíte nasledujúci výstup, v stĺpcoch Označenie, Zamestnanec_Názvy a Zamestnanec_Vek spočítajte čísla patriace do rovnakého mesta:
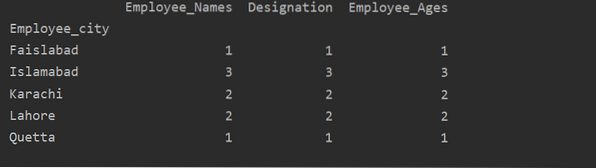
Vizualizujte údaje pomocou funkcie groupby
Použitím 'import matplotlib.pyplot ', môžete svoje údaje vizualizovať do grafov.
Príklad
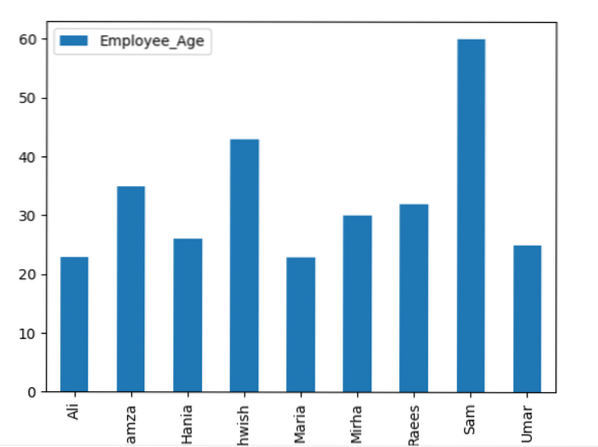
Nasledujúci príklad tu vizualizuje „Employee_Age“ s „Employee_Nmaes“ z daného DataFrame pomocou príkazu groupby.
importovať pandy ako pdimport matplotlib.pyplot ako plt
dátový rámec = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
dátový rámec.groupby ('Employee_Names').suma ().plot (druh = 'bar')
plt.šou()
Príklad
Ak chcete zostavený graf vykresliť pomocou funkcie groupby, otočte 'stacked = true' a použite nasledujúci kód:
importovať pandy ako pdimport matplotlib.pyplot ako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
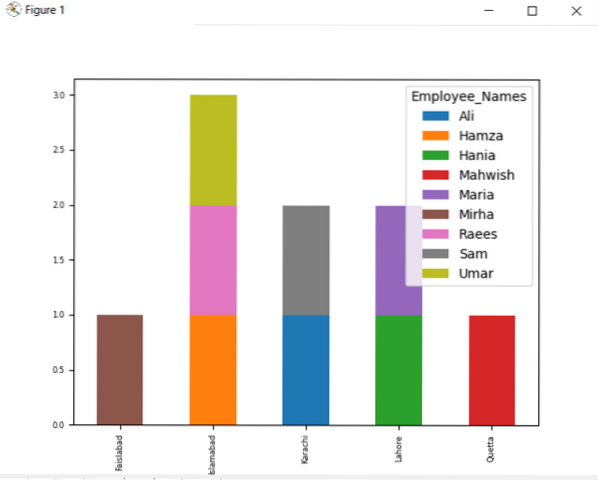
df.groupby ([['Employee_city', 'Employee_Names'])).veľkosť ().rozbaliť ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.šou()
V nižšie uvedenom grafe je uvedený počet zamestnancov, ktorí patria do rovnakého mesta.
Zmeňte názov stĺpca so skupinou podľa
Môžete tiež zmeniť názov súhrnného stĺpca s novým upraveným názvom takto:
importovať pandy ako pdimport matplotlib.pyplot ako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
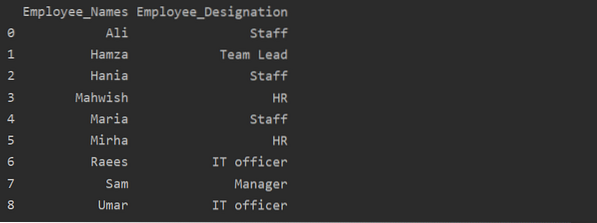
df1 = df.groupby ('Employee_Names') ['Označenie'].suma ().reset_index (name = 'Employee_Designation')
tlač (df1)
V uvedenom príklade sa názov „Označenie“ zmení na „Employee_Designation“.
Načítajte skupinu podľa kľúča alebo hodnoty
Pomocou príkazu groupby môžete načítať podobné záznamy alebo hodnoty z údajového rámca.
Príklad
V nižšie uvedenom príklade máme skupinové údaje založené na „označení“. Potom sa skupina 'Zamestnanci' vyvolá pomocou .getgroup („Zamestnanci“).
importovať pandy ako pdimport matplotlib.pyplot ako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby („Označenie“)
tlačiť (hodnota_výťažku.get_group ('Zamestnanci'))
V okne výstupu sa zobrazí nasledujúci výsledok:

Pridajte hodnotu do zoznamu skupín
Podobné údaje je možné zobraziť vo forme zoznamu pomocou príkazu groupby. Najskôr zoskupte údaje na základe podmienky. Potom pomocou funkcie môžete túto skupinu ľahko vložiť do zoznamov.
Príklad
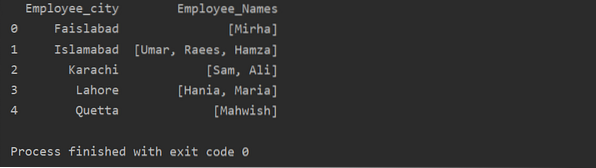
V tomto príklade sme vložili podobné záznamy do zoznamu skupín. Všetci zamestnanci sú rozdelení do skupiny na základe „Employee_city“ a potom pomocou funkcie „Lambda“ sa táto skupina získa vo forme zoznamu.
importovať pandy ako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].použiť (lambda group_series: group_series.listovať()).reset_index ()
tlač (df1)
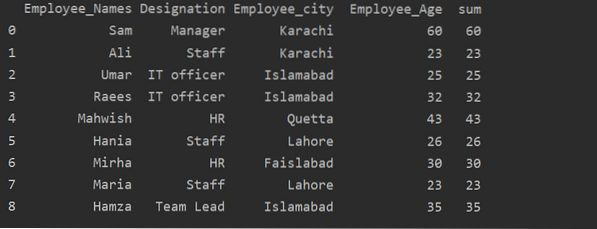
Použitie funkcie Transformácia s groupby
Zamestnanci sú zoskupení podľa veku, tieto hodnoty sa spočítajú a pomocou funkcie „transformácia“ sa do tabuľky pridá nový stĺpec:
importovať pandy ako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označenie“: [„Manažér“, „Zamestnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zamestnanci“, „HR“, „Zamestnanci“, „Vedúci tímu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['sum'] = df.groupby (['' Employee_Names ']) [' Employee_Age '].transformácia ('súčet')
tlačiť (df)
Záver
V tomto článku sme preskúmali rôzne použitia príkazu groupby. Ukázali sme, ako môžete rozdeliť údaje do skupín, a použitím rôznych agregácií alebo funkcií môžete tieto skupiny ľahko načítať.


