V tomto článku vám ukážem, ako vyhľadávať a vyberať prvky z webových stránok pomocou textu v seléne pomocou knižnice selén python. Takže poďme na to.
Predpoklady:
Ak chcete vyskúšať príkazy a príklady tohto článku, musíte mať:
- Vo vašom počítači je nainštalovaná distribúcia Linuxu (najlepšie Ubuntu).
- Python 3 nainštalovaný na vašom počítači.
- Vo vašom počítači je nainštalovaný program PIP 3.
- Python virtualenv balík nainštalovaný vo vašom počítači.
- Vo vašom počítači sú nainštalované webové prehľadávače Mozilla Firefox alebo Google Chrome.
- Musíte vedieť, ako nainštalovať ovládač Firefox Gecko alebo webový ovládač Chrome.
Pre splnenie požiadaviek 4, 5 a 6 si prečítajte môj článok Úvod do selénu v Pythone 3.
Mnoho článkov o ďalších témach nájdete na stránkach LinuxHint.com. Ak potrebujete pomoc, nezabudnite ich skontrolovať.
Nastavenie adresára projektu:
Ak chcete mať všetko usporiadané, vytvorte nový adresár projektu selén-výber textu / nasledovne:
$ mkdir -pv selén-text-výber / ovládače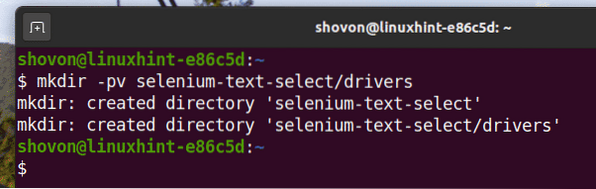
Prejdite na ikonu selén-výber textu / adresár projektu nasledovne:
$ cd selenium-text-select /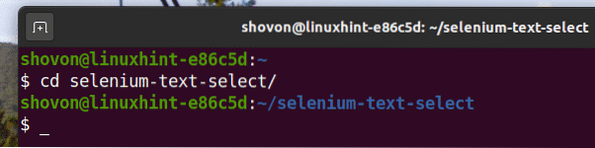
Vytvorte virtuálne prostredie Pythonu v adresári projektu takto:
$ virtualenv .venv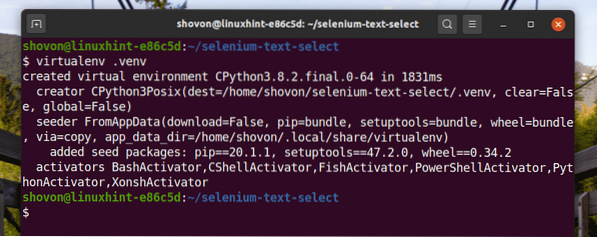
Aktivujte virtuálne prostredie nasledovne:
$ zdroj .venv / bin / aktivovať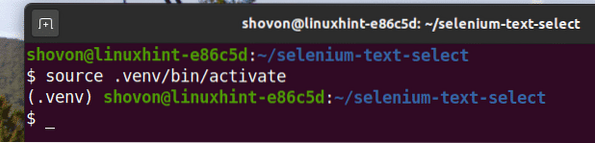
Nainštalujte knižnicu selénu Python pomocou PIP3 nasledovne:
$ pip3 nainštalujte selén
Stiahnite a nainštalujte všetky požadované webové ovládače v vodiči / adresár projektu. V mojom článku som vysvetlil proces sťahovania a inštalácie webových ovládačov Úvod do selénu v Pythone 3.
Hľadanie prvkov podľa textu:
V tejto časti vám ukážem niekoľko príkladov vyhľadávania a výberu prvkov webových stránok pomocou textu v knižnici Selenium Python.
Začnem najjednoduchším príkladom výberu prvkov webových stránok pomocou textu a výberom odkazov z webovej stránky.
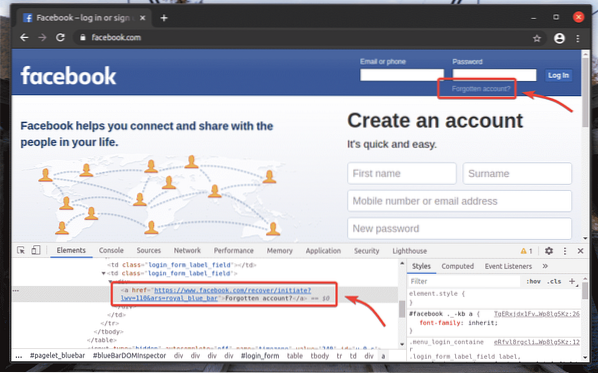
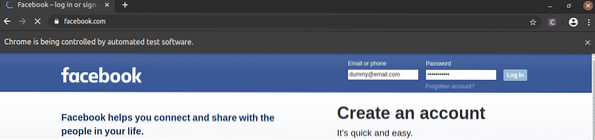
Na prihlasovacej stránke facebooku.sk, máme odkaz Zabudnutý účet? Ako môžete vidieť na snímke obrazovky nižšie. Vyberme tento odkaz so selénom.
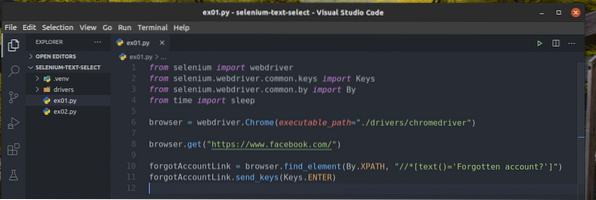
Vytvorte nový skript v jazyku Python ex01.py a zadajte do neho nasledujúce riadky kódov.
z webového ovládača na selén na importzo selénu.webdriver.bežné.kľúče na import kľúčov
zo selénu.webdriver.bežné.importom do
od času import spánku
prehliadač = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
prehliadač.get ("https: // www.Facebook.com / ")
zabudnutýAccountLink = prehliadač.find_element (podľa.XPATH, “
// * [text () = 'Zabudnutý účet?'] ")
zabudnutýAccountLink.send_keys (Klávesy.ENTER)
Po dokončení uložte súbor ex01.py Skript v jazyku Python.
Riadok 1-4 importuje všetky požadované komponenty do programu Python.

Riadok 6 vytvára Chrome prehliadač objekt pomocou chromedriver binárne z vodiči / adresár projektu.

Riadok 8 hovorí prehliadaču, aby načítal webovú stránku facebook.com.

Na riadku 10 sa nachádza odkaz, ktorý má text Zabudnutý účet? Pomocou selektora XPath. Na to som použil selektor XPath // * [text () = 'Zabudnutý účet?'].
Selektor XPath začína na //, čo znamená, že prvok môže byť kdekoľvek na stránke. The * symbol hovorí selénu, aby vybral ľubovoľnú značku (a alebo p alebo rozpätie, atď.), ktoré zodpovedajú podmienkam v hranatých zátvorkách []. Podmienkou je, že text prvku sa rovná Zabudnutý účet?

The text () Funkcia XPath sa používa na získanie textu prvku.
Napríklad, text () vracia Ahoj svet ak vyberie nasledujúci prvok HTML.
Ahoj svetRiadok 11 odošle

Spustite skript v jazyku Python ex01.py nasledujúcim príkazom:
$ python ex01.py
Ako vidíte, webový prehľadávač vyhľadá, vyberie a stlačí ikonu
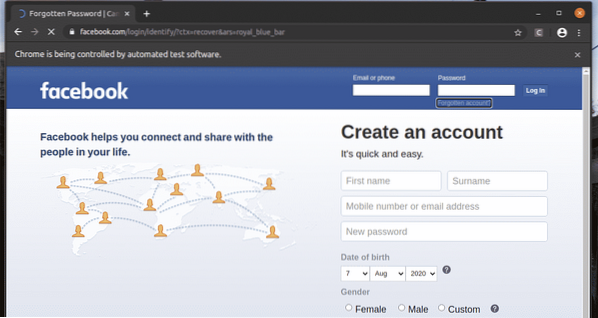
The Zabudnutý účet? Vďaka odkazu sa prehliadač presunie na nasledujúcu stránku.
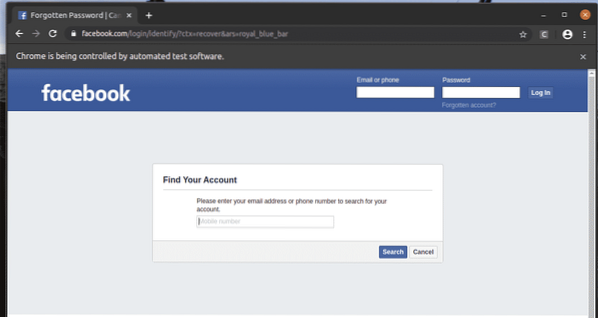
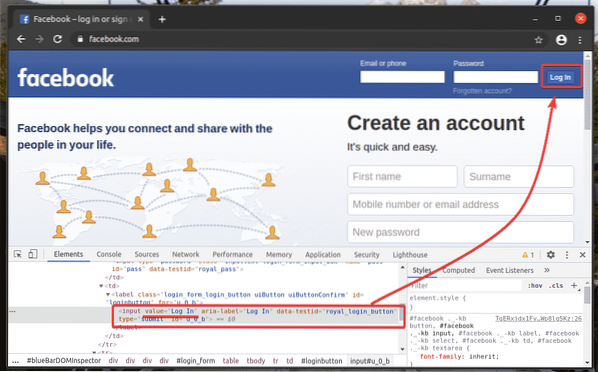
Rovnakým spôsobom môžete ľahko vyhľadať prvky, ktoré majú požadovanú hodnotu atribútu.
Tu je Prihlásiť sa tlačidlo je vstup prvok, ktorý má hodnotu atribút Prihlásiť sa. Pozrime sa, ako tento prvok vybrať pomocou textu.
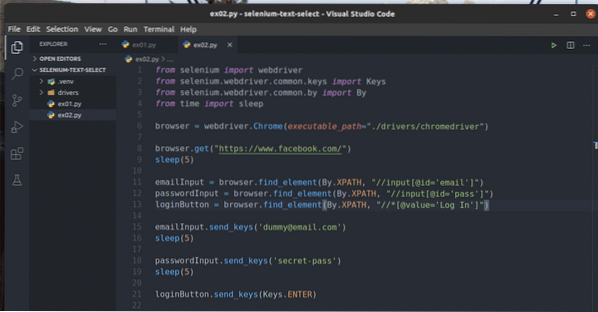
Vytvorte nový skript v jazyku Python ex02.py a zadajte do neho nasledujúce riadky kódov.
z webového ovládača na import selénuzo selénu.webdriver.bežné.kľúče na import kľúčov
zo selénu.webdriver.bežné.importom do
od času import spánku
prehliadač = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
prehliadač.get ("https: // www.Facebook.com / ")
spánok (5)
emailInput = prehliadač.find_element (podľa.XPATH, "// vstup [@ id = 'email']")
passwordInput = prehliadač.find_element (podľa.XPATH, "// vstup [@ id = 'pass']")
loginButton = prehliadač.find_element (podľa.XPATH, "// * [@ value = 'Prihlásiť sa']"))
emailInput.send_keys ('[e-mail chránený]')
spánok (5)
hesloVstup.send_keys ('secret-pass')
spánok (5)
loginButton.send_keys (Klávesy.ENTER)
Po dokončení uložte súbor ex02.py Skript v jazyku Python.
Riadok 1-4 importuje všetky požadované komponenty.

Riadok 6 vytvára Chrome prehliadač objekt pomocou chromedriver binárne z vodiči / adresár projektu.

Riadok 8 hovorí prehliadaču, aby načítal webovú stránku facebook.com.
Po spustení skriptu sa všetko deje tak rýchlo. Takže som použil spánok () fungovať mnohokrát v ex02.py pre oneskorenie príkazov prehliadača. Takto môžete sledovať, ako všetko funguje.

Riadok 11 vyhľadá textové pole na zadanie e-mailu a uloží odkaz na prvok v priečinku emailInput premenná.

Riadok 12 vyhľadá textové pole na zadanie e-mailu a uloží odkaz na prvok v emailInput premenná.

Riadok 13 vyhľadáva vstupný prvok, ktorý má atribút hodnotu z Prihlásiť sa pomocou selektora XPath. Na to som použil selektor XPath // * [@ value = 'Prihlásiť sa'].
Selektor XPath začína na //. Znamená to, že prvok môže byť kdekoľvek na stránke. The * symbol hovorí selénu, aby vybral ľubovoľnú značku (vstup alebo p alebo rozpätie, atď.), ktoré zodpovedajú podmienkam v hranatých zátvorkách []. Podmienkou je atribút element hodnotu rovná sa Prihlásiť sa.

Riadok 15 odošle vstup [chránený e-mailom] do textového poľa na zadanie e-mailu a riadok 16 oneskorí ďalšiu operáciu.

Riadok 18 odošle vstupné tajné heslo do textového poľa na zadanie hesla a riadok 19 oneskorí ďalšiu operáciu.

Riadok 21 odošle

Spustiť ex02.py Skript v jazyku Python s nasledujúcim príkazom:
$ python3 ex02.py
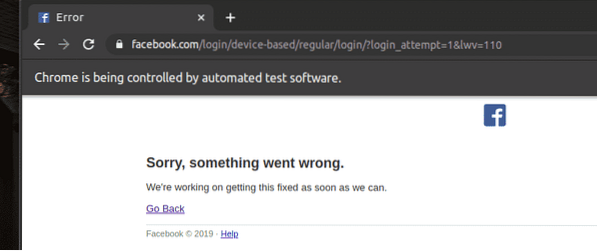
Ako vidíte, textové polia pre e-mail a heslo sú vyplnené našimi fiktívnymi hodnotami a znakom Prihlásiť sa je stlačené tlačidlo.
Potom stránka prejde na nasledujúcu stránku.
Hľadanie prvkov podľa čiastočného textu:
V predchádzajúcej časti som vám ukázal, ako nájsť prvky podľa konkrétneho textu. V tejto časti vám ukážem, ako nájsť prvky z webových stránok pomocou čiastočného textu.
V príklade, ex01.py, Hľadal som prvok odkazu, ktorý má text Zabudnutý účet?. Rovnaký prvok odkazu môžete prehľadať pomocou čiastočného textu, ako je napr Zabudnuté podľa. Môžete to urobiť pomocou obsahuje () Funkcia XPath, ako je uvedené v riadku 10 z ex03.py. Zvyšok kódov je rovnaký ako v ex01.py. Výsledky budú rovnaké.
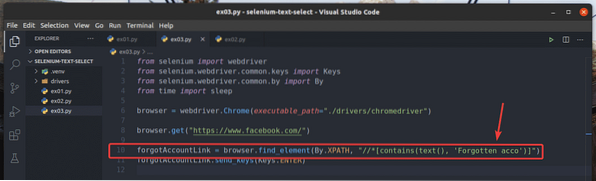
V riadku 10 z ex03.py, podmienka výberu použila obsahuje (zdroj, text) Funkcia XPath. Táto funkcia má 2 argumenty, zdroj, a text.
The obsahuje () funkcia kontroluje, či text uvedený v druhom argumente sa čiastočne zhoduje s zdroj hodnota v prvom argumente.
Zdrojom môže byť text prvku (text ()) alebo hodnotu atribútu prvku (@attr_name).
V ex03.py, skontroluje sa text prvku.

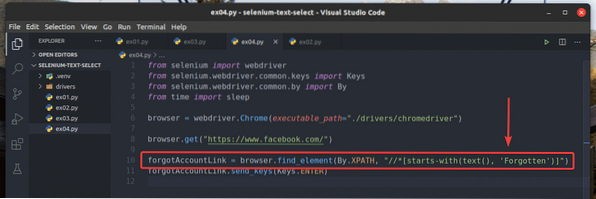
Ďalšou užitočnou funkciou XPath na vyhľadanie prvkov z webovej stránky pomocou čiastočného textu je Začína na (zdroj, text). Táto funkcia má rovnaké argumenty ako obsahuje () funkcie a používa sa rovnakým spôsobom. Rozdiel je iba v tom, že začína s() funkcia skontroluje, či je druhý argument text je počiatočný reťazec prvého argumentu zdroj.
Prepísal som príklad ex03.py vyhľadať prvok, pre ktorý text začína Zabudnuté, ako vidíte v riadku 10 z ex04.py. Výsledok je rovnaký ako v ex02 a ex03.py.
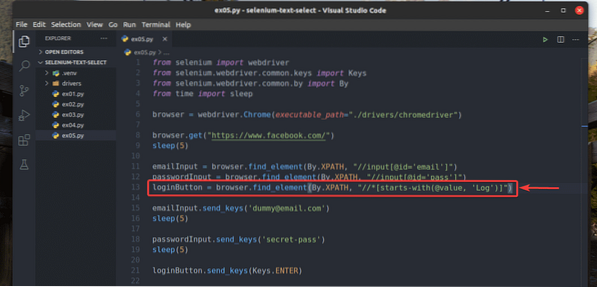
Aj som prepísal ex02.py tak, aby vyhľadal vstupný prvok, pre ktorý hodnotu atribút začína Log, ako vidíte v riadku 13 z ex05.py. Výsledok je rovnaký ako v ex02.py.
Záver:
V tomto článku som vám ukázal, ako vyhľadávať a vyberať prvky z webových stránok textom pomocou knižnice Selenium Python. Teraz by ste mali byť schopní nájsť prvky z webových stránok podľa konkrétneho textu alebo čiastočného textu pomocou knižnice Selenium Python.


