Celosvetový web je komplexným a konečným zdrojom všetkých údajov, ktoré tu sú. Rýchly rozvoj, ktorý internet zaznamenal za posledné tri desaťročia, bol bezprecedentný. Výsledkom je, že web sa každý deň pripája k stovkám terabajtov dát.
Všetky tieto údaje majú pre určitého niekoho hodnotu. Vaša história prehliadania má napríklad význam pre aplikácie sociálnych médií, pretože ju používajú na prispôsobenie reklám, ktoré vám zobrazujú. A aj pre tieto údaje existuje veľká konkurencia; o niekoľko MB viac niektorých údajov môže podnikom poskytnúť výrazný náskok pred ich konkurenciou.
Data mining s Pythonom
Aby sme pomohli tým z vás, ktorí sú v škrabaní údajov nováčikom, pripravili sme túto príručku, v ktorej ukážeme, ako škrabať údaje z webu pomocou knižnice Python a Krásna polievka.
Predpokladáme, že už máte stredne pokročilé znalosti jazyka Python a HTML, pretože s nimi budete pracovať podľa pokynov v tejto príručke.
Buďte opatrní, na ktorých weboch skúšate svoje nové vedomosti v oblasti ťažby dát, pretože mnoho webov to považuje za rušivé a vie, že by to mohlo mať dôsledky.
Inštalácia a príprava knižníc
Teraz použijeme dve knižnice, ktoré budeme používať: knižnicu požiadaviek pythonu na načítanie obsahu z webových stránok a knižnicu Beautiful Soup pre skutočný škrabanec procesu. Existujú alternatívy k BeautifulSoup, myslite na to, a ak ste oboznámení s jedným z nasledujúcich spôsobov, pokojne ich použite: Scrappy, Mechanize, Selenium, Portia, kimono a ParseHub.
Knižnicu požiadaviek je možné stiahnuť a nainštalovať pomocou príkazu pip, ako je uvedené nižšie:
# požiadavky na inštaláciu pip3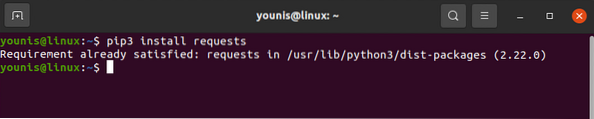
Knižnica žiadostí by mala byť nainštalovaná vo vašom zariadení. Podobne si stiahnite aj BeautifulSoup:
# pip3 nainštalujte beautifulsoup4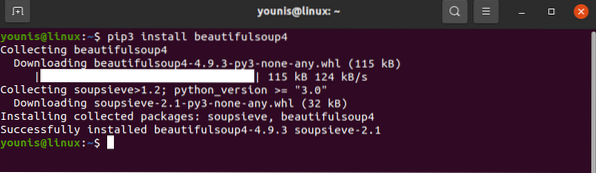
Vďaka tomu sú naše knižnice pripravené na akciu.
Ako už bolo spomenuté vyššie, knižnica požiadaviek nemá iné využitie ako načítanie obsahu z webových stránok. Knižnica a knižnice databáz BeautifulSoup majú miesto v každom skripte, ktorý budete písať, a musia byť pred každým importované nasledujúcim spôsobom:
$ požiadavky na import$ z bs4 importuje BeautifulSoup ako bs
Týmto sa do menného priestoru pridá požadované kľúčové slovo, ktoré Pythonu signalizuje jeho význam, kedykoľvek je vyzvané na jeho použitie. To isté sa stane s kľúčovým slovom bs, aj keď tu máme výhodu priradenia jednoduchšieho kľúčového slova pre BeautifulSoup.
webová stránka = požiadavky.získať (URL)Kód vyššie načíta adresu URL webovej stránky a vytvorí z nej priamy reťazec, ktorý uloží do premennej.
$ webcontent = webová stránka.obsahVyššie uvedený príkaz skopíruje obsah webovej stránky a priradí ho k variabilnému webovému obsahu.
S tým sme skončili s knižnicou požiadaviek. Ostáva už len zmeniť možnosti knižnice požiadaviek na možnosti BeautifulSoup.
$ htmlcontent = bs (webcontent, „html.analyzátor “)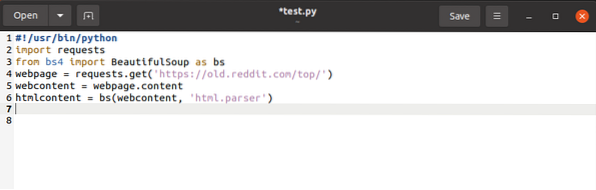
Toto analyzuje objekt žiadosti a zmení ho na čitateľné objekty HTML.
Keď je o to všetko postarané, môžeme prejsť na skutočný škrabací bit.
Škrabanie webu pomocou programov Python a BeautifulSoup
Poďme ďalej a pozrime sa, ako môžeme pomocou BeautifulSoup škrabať na dátové objekty HTML.
Na ilustráciu príkladu, zatiaľ čo vysvetľujeme veci, budeme pracovať s týmto útržkom html:
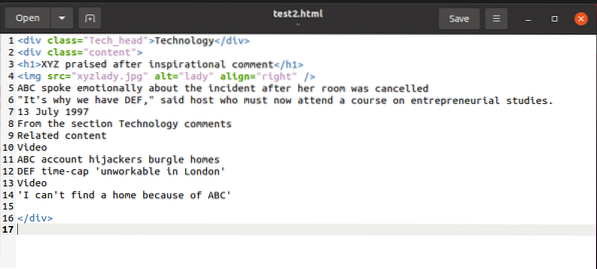
K obsahu tohto úryvku môžeme získať prístup pomocou nástroja BeautifulSoup a použiť ho v premennej obsahu HTML, ako je uvedené nižšie:
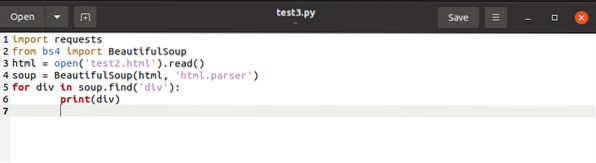
Vyššie uvedený kód vyhľadáva všetky pomenované značky
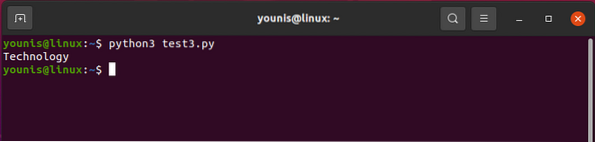
Ak chcete súčasne uložiť pomenované značky
do zoznamu, vydáme konečný kód ako v časti: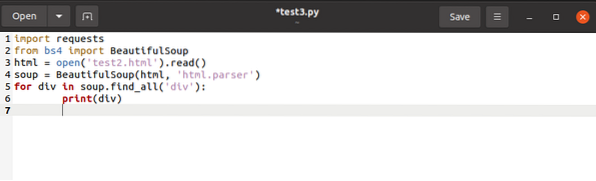
Výstup by sa mal vrátiť takto:
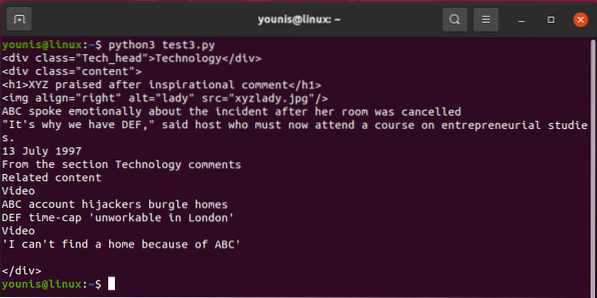
Privolať jedného z
Teraz sa pozrime, ako vybrať
značky udržujúce v perspektíve ich vlastnosti. Na oddelenie a , potrebovali by sme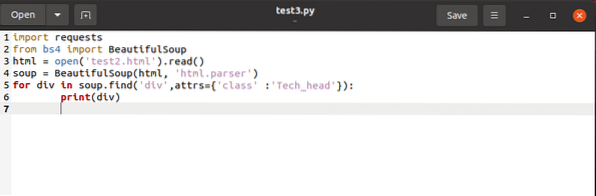
za div v polievke.find_all ('div', attrs = 'class' = 'Tech_head'):
Toto načíta
značka.Dostali by ste:
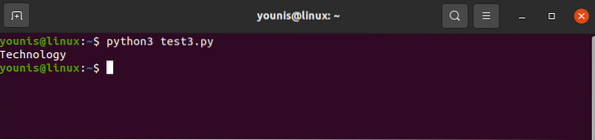
Technológie
Všetko bez značiek.
Na záver sa budeme venovať tomu, ako zistiť hodnotu atribútu v značke. Kód by mal mať túto značku:
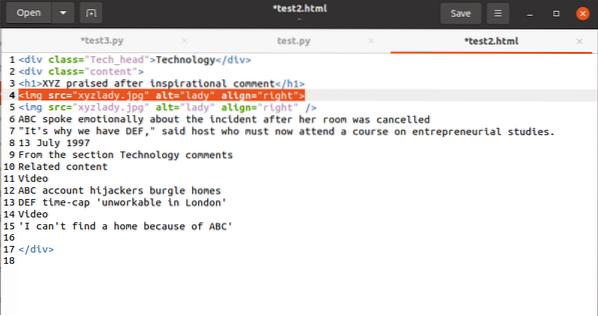

Na výpočet hodnoty spojenej s atribútom src použijete nasledovné:
htmlobsah.nájsť („img“) [„src“]A výstup by sa ukázal ako:
„images_4 / a-začiatočníci-sprievodca-web-škrabaním-s-python-a-krásnou-polievkou.jpg "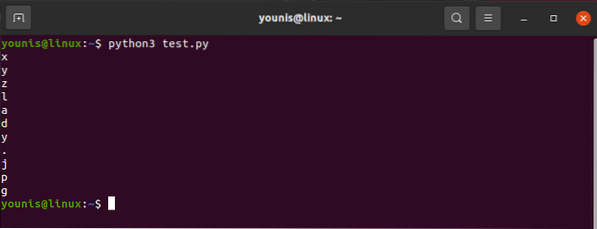
Och, chlapče, to je určite veľa práce!
Ak máte pocit, že vaša znalosť jazyka Python alebo HTML nie je dostatočná, alebo ak vás webový scraping jednoducho zavalil, nebojte sa.
Ak ste podnikom, ktorý potrebuje pravidelne získavať konkrétny typ údajov, ale nedokáže sám urobiť webový scraping, existujú spôsoby, ako tento problém vyriešiť. Ale vedzte, že vás to bude stáť nejaké peniaze. Môžete nájsť niekoho, kto za vás vykoná škrabanie, alebo môžete získať prémiovú dátovú službu z webov ako Google a Twitter, ktorá s vami bude zdieľať údaje. Tieto zdieľajú časti svojich údajov pomocou API, ale tieto hovory API sú obmedzené na deň. Okrem toho môžu webové stránky, ako sú tieto, veľmi chrániť svoje údaje. Mnoho takýchto stránok zvyčajne nezdieľa vôbec žiadne svoje údaje.
Záverečné myšlienky
Skôr ako skončíme, dovoľte mi, aby som vám nahlas povedal, či to už nebolo zrejmé; príkazy find (), find_all () sú vaši najlepší priatelia, keď sa chystáte zošrotovať s BeautifulSoup. Aj keď je tu oveľa viac, čo by ste si mali zahrnúť do škrabania kmeňových dát pomocou Pythonu, táto príručka by mala stačiť všetkým, ktorí práve začínate.


