V tejto lekcii o strojovom učení so scikit-learn sa dozvieme rôzne aspekty tohto vynikajúceho balíka Python, ktorý nám umožňuje aplikovať jednoduché a zložité schopnosti strojového učenia na rozmanitú sadu údajov spolu s funkciami na testovanie hypotézy, ktorú stanovíme.
Balík scikit-learn obsahuje jednoduché a efektívne nástroje na aplikáciu dolovania údajov a analýzy údajov v množinách údajov a tieto algoritmy sú k dispozícii na použitie v rôznych kontextoch. Jedná sa o balík open-source dostupný pod licenciou BSD, čo znamená, že túto knižnicu môžeme používať aj komerčne. Je postavený na matplotlib, NumPy a SciPy, takže má univerzálnu povahu. Na predstavenie príkladov v tejto lekcii využijeme program Anaconda s notebookom Jupyter.
Čo poskytuje scikit-learn?
Knižnica scikit-learn sa úplne zameriava na dátové modelovanie. Upozorňujeme, že v scikit-learn nie sú žiadne hlavné funkcie, pokiaľ ide o načítanie, manipuláciu a sumarizáciu údajov. Tu sú niektoré z populárnych modelov, ktoré nám scikit-learn poskytuje:
- Zhlukovanie do skupiny označených údajov
- Množiny údajov poskytovať testovacie dátové súbory a vyšetrovať modelové správanie
- Krížová validácia odhadnúť výkon dohliadaných modelov na neviditeľné údaje
- Metódy súboru kombinovať predpovede viacerých modelov pod dohľadom
- Extrakcia funkcií k definovaniu atribútov v obrazových a textových dátach
Nainštalujte si Python scikit-learn
Len na úvod pred začatím procesu inštalácie používame pre túto lekciu virtuálne prostredie, ktoré sme vytvorili pomocou nasledujúceho príkazu:
python -m virtualenv scikitzdrojový scikit / bin / aktivovať
Keď je virtuálne prostredie aktívne, môžeme si do virtuálneho env nainštalovať knižnicu pandas, aby bolo možné vykonať príklady, ktoré vytvoríme ďalej:
pip install scikit-learnAlebo môžeme použiť Condu na inštaláciu tohto balíka pomocou nasledujúceho príkazu:
conda nainštalovať scikit-learnVidíme niečo také, keď vykonáme vyššie uvedený príkaz:

Po dokončení inštalácie pomocou Condy budeme môcť balíček používať v našich skriptoch Pythonu ako:
import sklearnZačnime v našich skriptoch používať scikit-learn na vývoj úžasných algoritmov strojového učenia.
Importujú sa súbory údajov
Jednou zo skvelých vecí na scikit-learn je, že je predinštalovaný so vzorovými súbormi údajov, s ktorými je ľahké rýchlo začať. Dátové súbory sú dúhovka a číslice súbory údajov na klasifikáciu a ceny domov v bostone dataset pre regresne techniky. V tejto časti sa pozrieme na to, ako načítať a začať používať množinu údajov o clone.
Ak chcete importovať množinu údajov, najskôr musíme importovať správny modul, po ktorom nasleduje pozastavenie množiny údajov:
zo sklearn importu datasetoviris = súbory údajov.load_iris ()
číslice = súbory údajov.load_digits ()
číslice.údaje
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:

Celý výstup je kvôli stručnosti odstránený. Toto je množina údajov, ktorú budeme v tejto lekcii prevažne používať, ale väčšinu konceptov je možné aplikovať na všetky tieto množiny údajov.
Je len zábavnou skutočnosťou, že v serveri je prítomných viac modulov scikit ekosystém, z ktorých jeden je učiť sa používané pre algoritmy strojového učenia. Na tejto stránke nájdete mnoho ďalších prítomných modulov.
Preskúmanie datasetu
Teraz, keď sme do nášho skriptu importovali poskytnutú číselnú množinu údajov, mali by sme začať zhromažďovať základné informácie o množine údajov, a to tu urobíme. Pri hľadaní informácií o množine údajov by ste mali preskúmať základné veci:
- Cieľové hodnoty alebo štítky
- Atribút description
- Kľúče dostupné v danom súbore údajov
Poďme napísať krátky úryvok kódu, aby sme z nášho súboru údajov extrahovali tri vyššie uvedené informácie:
tlač („Cieľ:“, číslice.cieľ)tlač ('Kľúče:', číslice.klávesy ())
print ('Popis:', číslice.DESCR)
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:
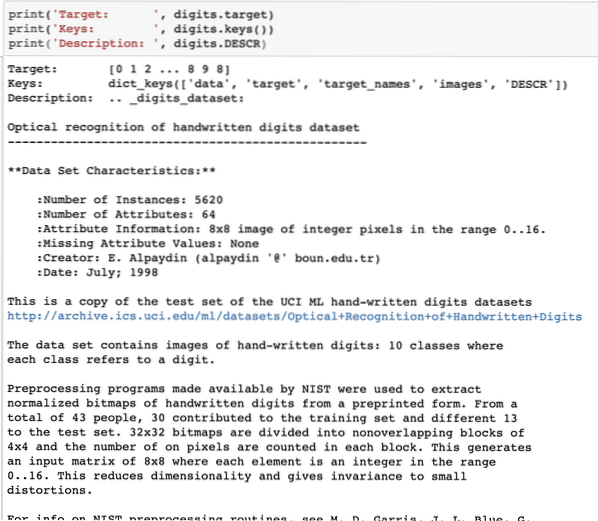
Upozorňujeme, že premenné číslice nie sú jednoznačné. Keď sme vytlačili číselný údajový súbor, skutočne obsahoval početné polia. Uvidíme, ako sa k týmto poliam dostaneme. Z tohto dôvodu si všimnite kľúče dostupné v inštancii číslic, ktoré sme vytlačili v poslednom fragmente kódu.
Začneme získaním tvaru údajov poľa, čo sú riadky a stĺpce, ktoré pole má. Najprv musíme získať skutočné údaje a potom získať ich tvar:
digits_set = digits.údajeprint (digits_set.tvar)
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:

To znamená, že v našom súbore údajov je prítomných 1797 vzoriek spolu so 64 údajovými funkciami (alebo stĺpcami). Máme tiež niekoľko cieľových štítkov, ktoré si tu vizualizujeme pomocou matplotlib. Tu je útržok kódu, ktorý nám k tomu pomáha:
import matplotlib.pyplot ako plt# Zlúčte obrázky a štítky cieľov do zoznamu
images_and_labels = zoznam (zip (číslice.obrázky, číslice.cieľ))
pre index (obrázok, štítok) v zozname (obrázky_a_štítky [: 8]):
# inicializuje subplot 2X4 na i + 1-tej pozícii
plt.subplot (2, 4, index + 1)
# Nie je potrebné vykresľovať žiadne osi
plt.os („vypnuté“)
# Zobraziť obrázky vo všetkých čiastkových obrázkoch
plt.imshow (obrázok, cmap = plt.cm.gray_r, interpolation = 'nearest')
# Pridajte názov do každého čiastkového grafu
plt.názov ('Training:' + str (štítok))
plt.šou()
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:

Všimnite si, ako sme spojili dve polia NumPy dohromady a potom sme ich vykreslili do mriežky 4 x 2 bez akýchkoľvek informácií o osiach. Teraz sme si istí informáciami, ktoré máme o množine údajov, s ktorou pracujeme.
Teraz, keď vieme, že máme 64 dátových funkcií (čo je mimochodom veľa funkcií), je náročné vizualizovať skutočné údaje. Máme na to však riešenie.
Analýza hlavných komponentov (PCA)
Toto nie je návod o PCA, ale poďme si urobiť malú predstavu o tom, čo to je. Pretože vieme, že na zníženie počtu funkcií z množiny údajov máme dve techniky:
- Vylúčenie funkcií
- Extrakcia funkcií
Zatiaľ čo prvá technika čelí problému stratených dátových funkcií, aj keď by mohli byť dôležité, druhá technika týmto problémom netrpí, pretože pomocou PCA konštruujeme nové dátové funkcie (v menšom počte), kde kombinujeme vstupné premenné takým spôsobom, že môžeme vynechať „najmenej dôležité“ premenné, pričom si ponecháme najcennejšie časti všetkých premenných.
Ako sa predpokladalo, DPS nám pomáha znižovať vysoko-dimenzionálnosť údajov čo je priamym výsledkom popisu objektu pomocou mnohých dátových funkcií. Nielen číslice, ale aj mnoho ďalších praktických súborov údajov má vysoký počet funkcií, ktoré zahŕňajú údaje o finančných inštitúciách, údaje o počasí a ekonomike pre región atď. Keď vykonávame PCA na číselnom súbore údajov, naším cieľom bude nájsť iba 2 vlastnosti, ktoré majú väčšinu charakteristík súboru údajov.
Poďme napísať jednoduchý útržok kódu na použitie PCA na číselnú množinu údajov, aby sme získali náš lineárny model pozostávajúci iba z dvoch funkcií:
od sklearn.dekompozícia import PCAfeature_pca = PCA (n_components = 2)
redukovaná_údajová_dáta = feature_pca.fit_transformácia (číslice.údaje)
model_pca = PCA (n_components = 2)
redukcia_data_pca = model_pca.fit_transformácia (číslice.údaje)
redukcia_data_pca.tvar
tlač (redukovaná_údajová_dáta)
tlač (redukcia_data_pca)
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:
[[-1.2594655 21.27488324][7.95762224 -20.76873116]
[6.99192123 -9.95598191]
…
[10.8012644 -6.96019661]
[-4.87210598 12.42397516]
[-0.34441647 6.36562581]]
[[-1.25946526 21.27487934]
[7.95761543 -20.76870705]
[6.99191947 -9.9559785]
…
[10.80128422 -6.96025542]
[-4.87210144 12.42396098]
[-0.3443928 6.36555416]]
Vo vyššie uvedenom kóde uvádzame, že pre množinu údajov potrebujeme iba dve funkcie.
Teraz, keď máme dobré vedomosti o našej množine údajov, sa môžeme rozhodnúť, aký druh algoritmov strojového učenia na ňu môžeme použiť. Znalosť datovej sady je dôležitá, pretože práve tak môžeme rozhodnúť o tom, aké informácie sa z nej dajú extrahovať a pomocou ktorých algoritmov. Pomáha nám tiež otestovať hypotézu, ktorú vytvoríme, pri predpovedaní budúcich hodnôt.
Aplikácia k-znamená zhlukovanie
Algoritmus klastrovania k-means je jedným z najjednoduchších klastrových algoritmov pre učenie bez dozoru. V tomto klastrovaní máme nejaký náhodný počet klastrov a naše dátové body klasifikujeme do jedného z týchto klastrov. Algoritmus k-means nájde najbližší zhluk pre každý z dátových bodov a priradí ich k tomuto zhluku.
Po dokončení klastrovania sa prepočíta stred klastra, dátovým bodom sa priraďujú nové klastre, ak dôjde k zmenám. Tento proces sa opakuje, kým sa dátové body tam prestanú meniť, aby dosiahli stabilitu.
Použime tento algoritmus jednoducho bez predbežného spracovania údajov. Pre túto stratégiu bude útržok kódu celkom jednoduchý:
z klastra sklearn importk = 3
k_means = zhluk.K Znamená (k)
# vhodné údaje
k_ znamená.fit (číslice.údaje)
# výsledky tlače
print (k_means.štítky _ [:: 10])
tlačiť (číslice.cieľ [:: 10])
Po spustení vyššie uvedeného útržku kódu sa nám zobrazí nasledujúci výstup:
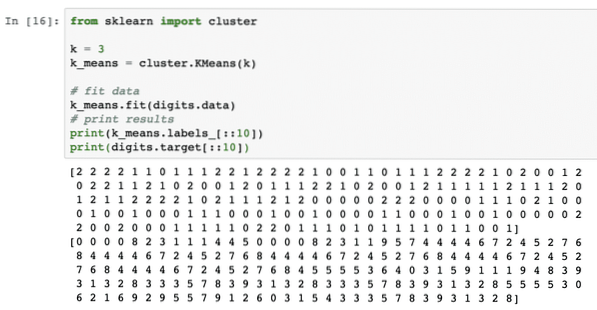
Vo vyššie uvedenom výstupe vidíme rôzne zhluky poskytované každému z údajových bodov.
Záver
V tejto lekcii sme sa pozreli na vynikajúcu knižnicu Machine Learning, scikit-learn. Dozvedeli sme sa, že v rodine scikit je k dispozícii mnoho ďalších modulov a na poskytnutú množinu údajov sme použili jednoduchý algoritmus k-means. Existuje mnoho ďalších algoritmov, ktoré je možné použiť na množinu údajov, okrem k-means klastrovania, ktoré sme použili v tejto lekcii, odporúčame vám, aby ste to robili a zdieľali svoje výsledky.
Podeľte sa o svoju spätnú väzbu k lekcii na Twitteri s @sbmaggarwal a @LinuxHint.


