Elasticsearch Databáza
Elasticsearch je jednou z najpopulárnejších databáz NoSQL, ktorá sa používa na ukladanie a vyhľadávanie textových údajov. Je založený na technológii indexovania Lucene a umožňuje vyhľadávanie v milisekundách na základe indexovaných údajov.
Na základe webovej stránky Elasticsearch je táto definícia:
Elasticsearch je distribuovaný open source, RESTful vyhľadávací a analytický modul schopný vyriešiť rastúci počet prípadov použitia.
To boli niektoré slová na vysokej úrovni o službe Elasticsearch. Poďme tu podrobne pochopiť pojmy.
- Distribuovaný: Elasticsearch rozdeľuje údaje, ktoré obsahuje, na viac uzlov a používa ich pán-otrok algoritmus interne
- RESTful: Elasticsearch podporuje databázové dotazy prostredníctvom rozhraní REST API. To znamená, že môžeme používať jednoduché hovory HTTP a používať metódy HTTP ako GET, POST, PUT, DELETE atď. na prístup k údajom.
- Vyhľadávací a analytický nástroj: ES podporuje vysoko analytické dotazy, ktoré sa majú spustiť v systéme a ktoré môžu pozostávať z agregovaných dotazov a viacerých typov, ako sú štruktúrované, neštruktúrované a geografické dotazy.
- Horizontálne škálovateľné: Tento druh škálovania sa týka pridania ďalších strojov do existujúceho klastra. To znamená, že ES je schopný prijať viac uzlov vo svojom klastri a neposkytnúť žiadne prestoje na požadované aktualizácie systému. Pozrieť sa na obrázok nižšie, aby ste pochopili koncepty zmeny mierky:
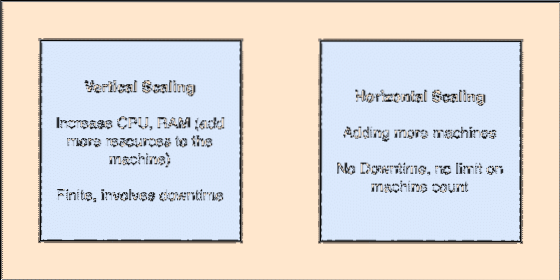
Vertikálne a horizontálne škálovanie
Začíname s databázou Elasticsearch
Ak chcete začať používať program Elasticsearch, musí byť na počítači nainštalovaný. Ak to chcete urobiť, prečítajte si článok Inštalácia ElasticSearch na Ubuntu.
Ak chcete vyskúšať príklady, ktoré uvedieme neskôr v lekcii, uistite sa, že máte aktívnu inštaláciu ElasticSearch.
Elasticsearch: Koncepty a komponenty
V tejto časti uvidíme, ktoré komponenty a koncepty ležia v srdci Elasticsearch. Pochopenie týchto pojmov je dôležité pre pochopenie toho, ako ES funguje:
- Klaster: Klaster je kolekcia serverových strojov (uzlov), ktorá uchováva údaje. Dáta sú rozdelené medzi viac uzlov, aby ich bolo možné replikovať, a pri serveri ES sa nestane jediný bod zlyhania (SPoF). Predvolený názov klastra je elasticsearch. Každý uzol v klastri sa pripája ku klastru pomocou adresy URL a názvu klastra, takže je dôležité, aby bol tento názov zreteľný a jasný.
- Uzol: Stroj uzla je súčasťou servera a označuje sa ako jeden stroj. Ukladá údaje a poskytuje indexovanie a možnosti vyhľadávania spolu s ostatnými uzlami klastra.
Vďaka konceptu horizontálneho škálovania môžeme virtuálne pridať nekonečné množstvo uzlov do klastra ES, aby sme mu poskytli oveľa väčšiu silu a možnosti indexovania.
- Register: Register je zbierka dokumentov s trochu podobnými vlastnosťami. Index je skoro podobný databáze v prostredí založenom na SQL.
- Typ: Typ sa používa na oddelenie údajov medzi rovnakým indexom. Napríklad Zákaznícka databáza / index môže mať niekoľko typov, ako napríklad používateľ, typ_platby atď.
Upozorňujeme, že podpora typov od verzie ES v6 je ukončená.0.0 a ďalej. Prečítajte si, prečo sa to stalo.
- Dokument: Dokument je najnižšia úroveň jednotky, ktorá predstavuje údaje. Predstavte si to ako objekt JSON, ktorý obsahuje vaše údaje. V indexe je možné indexovať toľko dokumentov.
Typy vyhľadávania v službe Elasticsearch
Elasticsearch je známy svojimi schopnosťami vyhľadávania takmer v reálnom čase a flexibilitou, ktorú poskytuje pri type indexovaných a prehľadávaných údajov. Začnime študovať, ako používať vyhľadávanie s rôznymi typmi údajov.
- Štruktúrované vyhľadávanie: Tento typ vyhľadávania sa spúšťa na dátach, ktoré majú vopred definovaný formát, ako sú Dátumy, časy a čísla. S vopred definovaným formátom prichádza flexibilita pri spúšťaní bežných operácií, ako je porovnávanie hodnôt v rozsahu dátumov. Zaujímavé, môžu byť štruktúrované aj textové údaje. To sa môže stať, keď má pole pevný počet hodnôt. Napríklad názov databáz môže byť, MySQL, MongoDB, Elasticsearch, Neo4J atď. Vďaka štruktúrovanému vyhľadávaniu je odpoveď na kladené otázky buď áno, alebo nie.
- Fulltextové vyhľadávanie: Tento typ vyhľadávania závisí od dvoch dôležitých faktorov, Relevantnosť a Analýza. Pomocou Relevancie určujeme, ako dobre sa niektoré údaje zhodujú s dotazom, definovaním skóre výsledných dokumentov. Toto skóre poskytuje samotný ES. Analýza označuje rozdelenie textu na normalizované tokeny, aby sa vytvoril obrátený index.
- Vyhľadávanie viacerých polí: S počtom analytických dotazov, ktoré sa v súvislosti s uloženými údajmi v ES neustále zvyšujú, sa zvyčajne nestretávame s jednoduchými dotazmi na zhody. Narástli požiadavky na spustenie dotazov, ktoré sa rozprestierajú na viacerých poliach a majú skórovaný zoradený zoznam údajov, ktoré nám vrátila samotná databáza. Takto môžu byť údaje koncovému používateľovi poskytnuté oveľa efektívnejšie.
- Proimity Matching: Dopyty dnes nie sú len identifikáciou toho, či niektoré textové údaje obsahujú iný reťazec alebo nie. Ide o vytvorenie vzťahu medzi údajmi, aby bolo možné ich vyhodnotiť a porovnať s kontextom, v ktorom sa údaje porovnávajú. Napríklad:
- Lopta zasiahla Johna
- John trafil loptu
- John kúpil nový ples, ktorý bol zasiahnutý do záhrady Jaen
Pri hľadaní zhody vyhľadajú všetky tri dokumenty Lopta zasiahla. Blízke vyhľadávanie nám môže povedať, ako ďaleko sa tieto dve slová objavujú v rovnakom riadku alebo odseku, kvôli ktorému sa zhodovali.
- Čiastočné zhody: Často je potrebné spustiť dotazy na čiastočné zhody. Čiastočné priraďovanie nám umožňuje spúšťať dotazy, ktoré sa čiastočne zhodujú. Aby sme si to vizualizovali, pozrime sa na podobné dotazy založené na SQL:
SQL dotazy: Čiastočné priraďovanie
KDE názov ako „% john%“
AND meno AKO „% red%“
AND meno AKO „% garden%“V niektorých prípadoch stačí spustiť dotazy na čiastočnú zhodu, aj keď sa dajú považovať za techniky brutálnej sily.
Integrácia s Kibanou
Pokiaľ ide o analytický nástroj, zvyčajne musíme spúšťať analytické dotazy v doméne Business-Intelligence (BI). Pokiaľ ide o obchodných analytikov alebo dátových analytikov, nebolo by spravodlivé predpokladať, že ľudia vedia programovací jazyk, keď chcú vizualizovať údaje prítomné v ES Clusteri. Tento problém rieši Kibana. Kibana ponúka toľko výhod pre BI, že ľudia môžu skutočne vizualizovať údaje pomocou vynikajúceho prispôsobiteľného panela a vidieť dáta neprakticky. Pozrime sa tu na niektoré z jeho výhod.
Interaktívne grafy
Jadrom Kibany sú interaktívne grafy, ako sú tieto: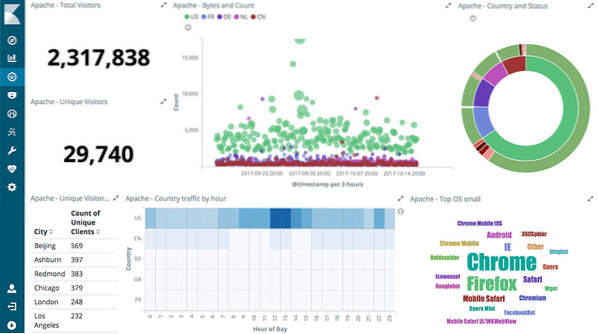
Kibana je podporovaná rôznymi typmi grafov, ako sú koláčové grafy, výboje slnka, histogramy a oveľa viac, ktoré využívajú kompletné agregačné možnosti ES.
Podpora mapovania
Kibana tiež podporuje úplnú geografickú agregáciu, ktorá nám umožňuje geograficky mapovať naše údaje. Nie je to v pohode?!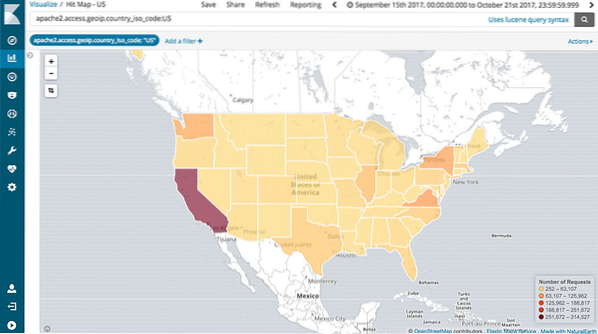
Vopred pripravené agregácie a filtre
Pomocou vopred pripravených agregácií a filtrov je možné v rámci Kibana Dashboard doslova fragmentovať, púšťať a spúšťať vysoko optimalizované dotazy. Iba niekoľkými kliknutiami je možné spustiť agregované dotazy a prezentovať výsledky vo forme interaktívnych grafov.
Ľahká distribúcia informačných panelov
S Kibanou je tiež veľmi ľahké zdieľať dashboardy s oveľa širším publikom bez vykonávania akýchkoľvek zmien na dashboarde pomocou režimu Dashboard Only. Panely dashboard môžeme ľahko vložiť na našu internú wiki alebo webovú stránku.
Hlavné obrázky vytvorené z produktovej stránky Kibana.
Pomocou Elasticsearch
Ak chcete zobraziť podrobnosti inštancie a informácie o klastri, spustite nasledujúci príkaz: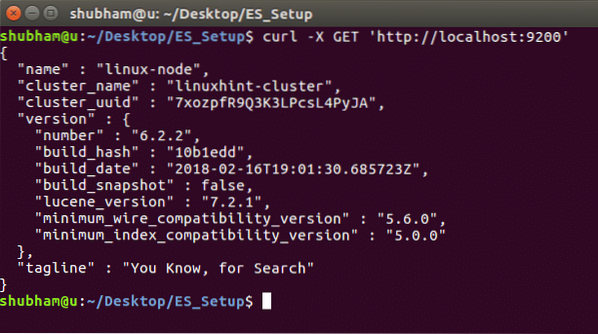
Teraz môžeme skúsiť vložiť niektoré dáta do ES pomocou nasledujúceho príkazu:
Vkladanie údajov
zvlnenie \-X POST 'http: // localhost: 9200 / linuxhint / ahoj / 1' \
-H „Typ obsahu: aplikácia / json“ \
-d '"name": "LinuxHint"' \
S týmto príkazom sa dostaneme späť:
Pokúsme sa získať údaje teraz:
Získavanie údajov
curl -X ZÍSKAJTE 'http: // localhost: 9200 / linuxhint / ahoj / 1'Keď spustíme tento príkaz, dostaneme nasledujúci výstup:
Záver
V tejto lekcii sme sa pozreli na to, ako môžeme začať používať ElasticSearch, ktorý je vynikajúcim nástrojom Analytics a poskytuje vynikajúcu podporu aj pre vyhľadávanie vo voľnom texte v reálnom čase.


